
ใน ep ที่แล้ว เราใช้ Pandas Profiling ในการช่วยทำการสำรวจข้อมูล Exploratory Data Analysis (EDA) แต่ถ้าเราต้องการเปลี่ยนแปลงข้อมูลนิด ๆ หน่อย ๆ หรือเราต้องการพล็อตกราฟที่ใน Pandas Profiling ไม่มีมาให้ล่ะ จะทำอย่างไร เราสามารถใช้ Pandas_UI มาช่วยได้
Category Archives: Tabular Data
สอน PyTorch ฟังก์ชัน gather เลือกข้อมูล จาก Tensor หลายมิติ – Tensor ep.4
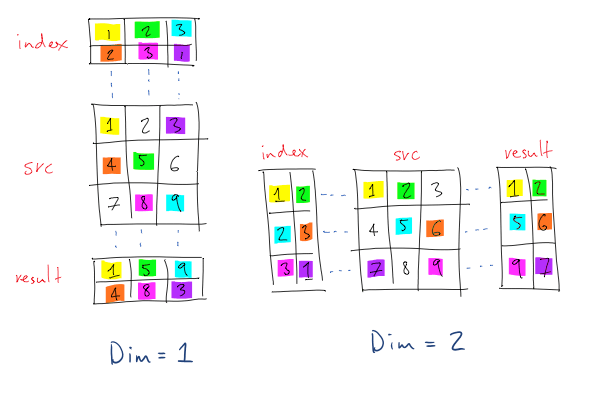
ใน ep ก่อน ๆ เราได้เรียนรู้ Tensor การจัดการมิติ การเลือกข้อมูลด้วย indexing, slicing กันไปแล้ว ใน ep นี้ เราจะมาเรียนรู้การเลือกข้อมูล Tensor ที่ซับซ้อนยิ่งขึ้น ด้วย gather อ่านเอกสารแล้วอาจจะยังงง เรามาดูตัวอย่างกันเลยดีกว่า
ชุดข้อมูล Dataset COVID-19 Coronavirus Time series Data การระบาดของเชื้อไวรัสโคโรนา โรคโควิด-19
ชุดข้อมูล Time series การระบาด Pandemic ของเชื้อไวรัสโคโรนา โรคโควิด-19 (Coronavirus COVID-19) จากหลายประเทศทั่วโลก ที่องค์กรต่าง ๆ ช่วยกันรวบรวมมา ในรูปแบบไฟล์ CSV, JSON, REST API, Shape file, Excel อัพเดททุกวัน เราสามารถนำชุดข้อมูลนี้มาทำ Visualization และวิเคราะห์ด้วยโมเดลแบบจำลองต่าง ๆ ต่อไป
Customer Segmentation คืออะไร สอนทฤษฎี Machine Learning หลักการ สร้าง Segment Profile กลุ่มลูกค้า, Customer Profile การแบ่งกลุ่มลูกค้า ด้วย K-Means Clustering – Tabular Data ep.4

ใน ep นี้ เราจะมาวิเคราะห์ Customer Segment สอนทฤษฎี Machine Learning การแบ่งกลุ่มลูกค้า Customer Segmentation หรือ Market Segmentation หลักการ สร้าง Segment Profile กลุ่มลูกค้า, Customer Profile ด้วย K-Means Clustering ซึ่งเป็น Machine Learning แบบ Unsupervised Learning เป็น Algorithm ที่เรียบง่าย และนิยมใช้ใงาน Customer Relationship Management, Business Model Canvas
จัดการหมวดหมู่เล็ก ๆ ยิบย่อย รวมข้อมูลหมวดหมู่ Category เล็ก ๆ เป็นหมวดหมู่ Other ก่อนป้อนเทรน Machine Learning – Preprocessing ep.4
ในหลาย ๆ Dataset เราจะพบว่าข้อมูลแบบ Category มีการแตกยิบย่อยมากเกินไป เช่น บาง Category มีแค่ 1 หรือ 2 Record เท่านั้น หรือ Category เล็ก จำนวน Record แตกต่างกับ Category ใหญ่ ๆ หลายร้อย หลายพันเท่า ข้อมูล Category เล็ก ๆ ยิบย่อยเหล่านี้ อาจจะไม่ได้ช่วยโมเดล Machine Learning ในการเรียนรู้ก็ได้ ทางแก้คือ เราจะ Group รวม Category เล็ก ๆ เหล่านั้นรวมออกมาเป็น Category ใหม่ ตั้งชื่อว่า Other
สำรวจข้อมูล Exploratory Data Analysis (EDA) ด้วย Pandas Profiling วิเคราะห์ Pandas DataFrame – Pandas ep.6
เมื่อเราได้ Dataset ใหม่มา สิ่งแรกที่เราควรทำ คือ Exploratory Data Analysis (EDA) ทำความเข้าใจข้อมูล ในแต่ละ Feaure เช่น ข้อมูลเป็นชนิดอะไร, ข้อมูลเป็นแบบต่อเนื่องหรือไม่ต่อเนื่อง, ช่วงของข้อมูลกว้างแค่ไหน, การกระจายของข้อมูลเป็นอย่างไร, มีข้อมูลขาดหายไปเยอะแค่ไหน, แต่ละ Feature เชื่อมโยงกันอย่างไร การวิเคราะห์ทั้งหมดนี้ค่อนข้างซับซ้อน และซ้ำซ้อนเหมือนกันในทุก ๆ Dataset จะมีวิธีไหนที่จะทำให้งานซ้ำ ๆ เหล่านี้ง่ายขึ้น
Categorize การเตรียมข้อมูลหมวดหมู่ Categorical Data ด้วย One-Hot Encoding, Map ก่อนเทรน Machine Learning – Preprocessing ep.3
นอกเหนือจากข้อมูลตัวเลข Cardinal ค่าต่อเนื่อง (Continuous) เราจะพบ Feature ที่เป็นข้อมูลค่าไม่ต่อเนื่อง (Discrete) ในรูปแบบตัวเลขแบบ Ordinal, Nominal หรือข้อความ คือ มีค่าที่เป็นไปได้จำกัด ระบุว่าอยู่หมวดหมู่ไหน เช่น วันในสัปดาห์ 1 จันทร์, 2 อังคาร, 3 พุธ, … คือ 1 ใน 7 ค่าเท่านั้น เราจะไม่สามารถทำ Rescale, Normalize แบบใน ep 2 ได้ แล้วเราจะเตรียมข้อมูลชนิดนี้อย่างไรดี ถึงจะป้อนให้ Machine Learning ใช้เทรนได้
Normalization คืออะไร ปรับช่วงข้อมูล Feature Scaling ด้วยวิธี Normalization, Standardization ก่อนเทรน Machine Learning – Preprocessing ep.2
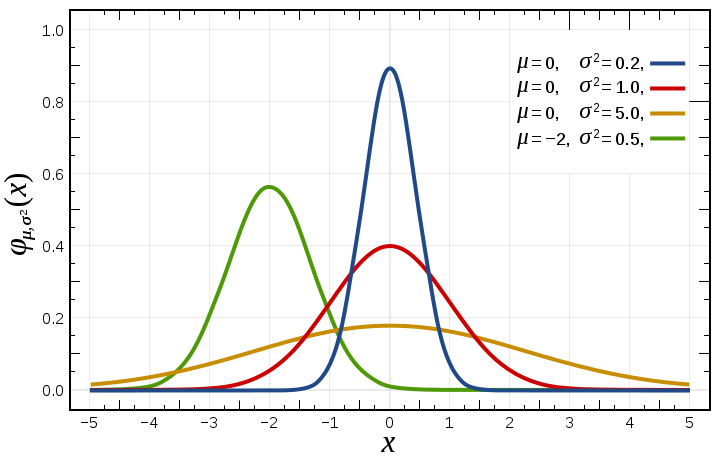
การทำ Feature Scaling คือ วิธีการปรับช่วงขอบเขตของข้อมูลชนิดตัวเลข Cardinal แต่ละ Feature (Field) ให้อยู่ในช่วงเดียวกัน ที่เหมาะกับการนำไปประมวลผลต่อ เข้าสูตรคำนวณได้ง่าย เช่น ช่วง [0, 1] หรือ [-1, 1] ได้ผลลัพธ์อยู่ในช่วงที่กำหนด เรียกว่า Data Normalization นิยมทำในขั้นตอน Preprocessing จัดเตรียมข้อมูล ก่อนป้อนให้โมเดลใช้เทรน
Preprocessing คืออะไร สอนจัดการข้อมูลขาดหาย Missing Value วิธีเติมข้อมูลแทนค่า Null, NA, NaN ก่อนป้อนโมเดล เทรน Machine Learning – Preprocessing ep.1

จาก ep ก่อน ที่เราสอนเรื่อง ใช้ Deep Neural Network วิเคราะห์ข้อมูลแบบ Structure หรือข้อมูลแบบตาราง Tabular Data จะมีงานสำคัญที่ต้องทำก่อนเทรน คือการ Preprocessing จัดเตรียมข้อมูล ซึ่งมีหลายอย่าง เช่น Fillna, Normalize, Categorize, Clipping, Binning, Feature Engineering ต่าง ๆ , etc. ใน ep นี้เราจะมาเรียนรู้กันเรื่อง การจัดการกับข้อมูลไม่ครบ วิธีเติมค่าที่ขาดหายไป หรือ Null
สับไพ่ข้อมูล DataLoader ด้วย Random Sampler และ Collate ป้อนโมเดล เทรน Machine Learning – Neural Network ep.7

ในแต่ละ Epoch ของการเทรน Machine Learning สอนโมเดล Deep Neural Network เราไม่ควรป้อนข้อมูลที่เรียงลำดับเหมือนกันทุกครั้งให้โมเดล ใน ep นี้เราจะมาสร้าง DataLoader เวอร์ชันใหม่ ที่จะสับไพ่ข้อมูลตัวอย่างก่อนป้อนให้โมเดล เป็นการลดการจำข้อสอบของโมเดล ช่วยให้โมเดล Generalization ได้ดีขึ้น ลด Variance ของโมเดล