อย่างที่เราทราบกันดีว่า I/O หรือระบบ Input/Output เป็นอะไรที่ช้าที่สุด ของระบบคอมพิวเตอร์ การที่จะ Optimize ให้คอมพิวเตอร์ทำงานได้ประสิทธิภาพมากที่สุด ต้องใช้ความรู้ความเข้าใจ บริหารจัดการทรัพยากรส่วนต่าง ๆ เช่น CPU, GPU, Memory, Storage, Network ให้ทำงาน Utilize มากที่สุด ลด Bottleneck ที่ต้องรอข้อมูลระหว่างกัน แต่ในการเทรน Machine Learning ที่เราวิธีที่เราทำกันอยู่ Training Loop จะเริ่มต้นจาก อ่านข้อมูล, สับไพ่ข้อมูล, Split, Data Augmentation, Feed Forward, Loss Function, Backpropagation, Optimizer Update Weight แล้วเริ่มต้น Loop ใหม่ เป็นอย่างนี้ซ้ำ ๆ ไปเรื่อย ๆ ตามลำดับ โดยไม่ได้คำนึงถึงประเด็นด้านบน แล้วเราจะแก้ไขอย่างไร
Tag Archives: preprocessing
Data Pipeline คืออะไร Data Block API สร้าง Data Pipeline สำหรับเทรน Machine Learning แบบ Supervised Learning – Preprocessing ep.5

ในการเทรน Machine Learning โดยเฉพาะแบบ Supervised Learning หรือข้อมูลมี Label นอกจากเรื่องการเทรน การออกแบบสถาปัตยกรรมของโมเดล ยังมีงานสำคัญอีกหลายที่ต้องทำก่อนที่เราจะเริ่มเทรนได้ หนึ่งในนั้นคือ สร้าง Data Pipeline จัดเตรียมข้อมูล
จัดการหมวดหมู่เล็ก ๆ ยิบย่อย รวมข้อมูลหมวดหมู่ Category เล็ก ๆ เป็นหมวดหมู่ Other ก่อนป้อนเทรน Machine Learning – Preprocessing ep.4
ในหลาย ๆ Dataset เราจะพบว่าข้อมูลแบบ Category มีการแตกยิบย่อยมากเกินไป เช่น บาง Category มีแค่ 1 หรือ 2 Record เท่านั้น หรือ Category เล็ก จำนวน Record แตกต่างกับ Category ใหญ่ ๆ หลายร้อย หลายพันเท่า ข้อมูล Category เล็ก ๆ ยิบย่อยเหล่านี้ อาจจะไม่ได้ช่วยโมเดล Machine Learning ในการเรียนรู้ก็ได้ ทางแก้คือ เราจะ Group รวม Category เล็ก ๆ เหล่านั้นรวมออกมาเป็น Category ใหม่ ตั้งชื่อว่า Other
Categorize การเตรียมข้อมูลหมวดหมู่ Categorical Data ด้วย One-Hot Encoding, Map ก่อนเทรน Machine Learning – Preprocessing ep.3
นอกเหนือจากข้อมูลตัวเลข Cardinal ค่าต่อเนื่อง (Continuous) เราจะพบ Feature ที่เป็นข้อมูลค่าไม่ต่อเนื่อง (Discrete) ในรูปแบบตัวเลขแบบ Ordinal, Nominal หรือข้อความ คือ มีค่าที่เป็นไปได้จำกัด ระบุว่าอยู่หมวดหมู่ไหน เช่น วันในสัปดาห์ 1 จันทร์, 2 อังคาร, 3 พุธ, … คือ 1 ใน 7 ค่าเท่านั้น เราจะไม่สามารถทำ Rescale, Normalize แบบใน ep 2 ได้ แล้วเราจะเตรียมข้อมูลชนิดนี้อย่างไรดี ถึงจะป้อนให้ Machine Learning ใช้เทรนได้
Normalization คืออะไร ปรับช่วงข้อมูล Feature Scaling ด้วยวิธี Normalization, Standardization ก่อนเทรน Machine Learning – Preprocessing ep.2
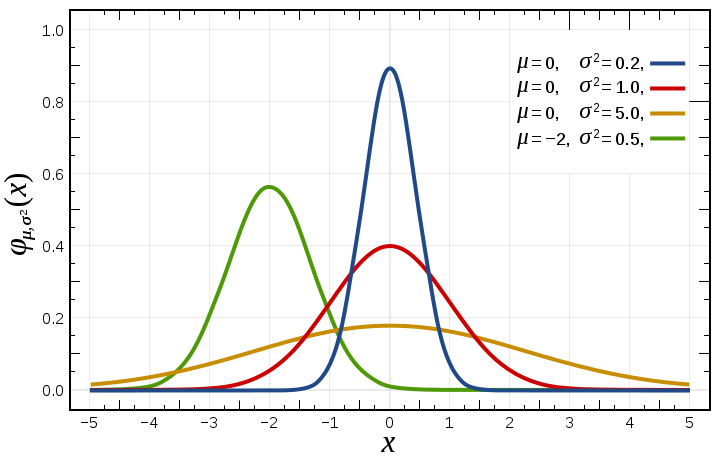
การทำ Feature Scaling คือ วิธีการปรับช่วงขอบเขตของข้อมูลชนิดตัวเลข Cardinal แต่ละ Feature (Field) ให้อยู่ในช่วงเดียวกัน ที่เหมาะกับการนำไปประมวลผลต่อ เข้าสูตรคำนวณได้ง่าย เช่น ช่วง [0, 1] หรือ [-1, 1] ได้ผลลัพธ์อยู่ในช่วงที่กำหนด เรียกว่า Data Normalization นิยมทำในขั้นตอน Preprocessing จัดเตรียมข้อมูล ก่อนป้อนให้โมเดลใช้เทรน
Preprocessing คืออะไร สอนจัดการข้อมูลขาดหาย Missing Value วิธีเติมข้อมูลแทนค่า Null, NA, NaN ก่อนป้อนโมเดล เทรน Machine Learning – Preprocessing ep.1

จาก ep ก่อน ที่เราสอนเรื่อง ใช้ Deep Neural Network วิเคราะห์ข้อมูลแบบ Structure หรือข้อมูลแบบตาราง Tabular Data จะมีงานสำคัญที่ต้องทำก่อนเทรน คือการ Preprocessing จัดเตรียมข้อมูล ซึ่งมีหลายอย่าง เช่น Fillna, Normalize, Categorize, Clipping, Binning, Feature Engineering ต่าง ๆ , etc. ใน ep นี้เราจะมาเรียนรู้กันเรื่อง การจัดการกับข้อมูลไม่ครบ วิธีเติมค่าที่ขาดหายไป หรือ Null