
ในการเทรน Machine Learning โดยเฉพาะแบบ Supervised Learning หรือข้อมูลมี Label นอกจากเรื่องการเทรน การออกแบบสถาปัตยกรรมของโมเดล ยังมีงานสำคัญอีกหลายที่ต้องทำก่อนที่เราจะเริ่มเทรนได้ หนึ่งในนั้นคือ สร้าง Data Pipeline จัดเตรียมข้อมูล
Tag Archives: minibatch
Layer-Sequential Unit-Variance Initialization (LSUV) คืออะไร แตกต่างกับ Kaiming อย่างไร ในการ Initialize Deep Neural Network – ConvNet ep.6

จากใน ep ก่อน เราได้เรียนรู้การสร้าง ConvNet ขึ้นมาจากหลายส่วนประกอบด้วยกัน และเมื่อสร้างโมเดลขึ้นมาแล้ว ก่อนเทรนเราจำเป็นต้อง Initialize Parameter (Weight, Bias) ต่าง ๆ ด้วยค่าที่เหมาะสม ใน ep ที่แล้ว เราใช้ Kaiming Initalization แล้วถ้าโมเดลเราเกิดซับซ้อนขึ้นเรื่อย ๆ ล่ะ เช่น มีการเปลี่ยน Activaiton Function, มี Skip Connection, มีหลาย Input, เพิ่ม BatchNorm แบบต่าง ๆ, etc. จะทำอย่างไร
BatchNorm คืออะไร สอน Batch Normalization เทรน Machine Learning โมเดล Deep Convolutional Neural Network – ConvNet ep.5
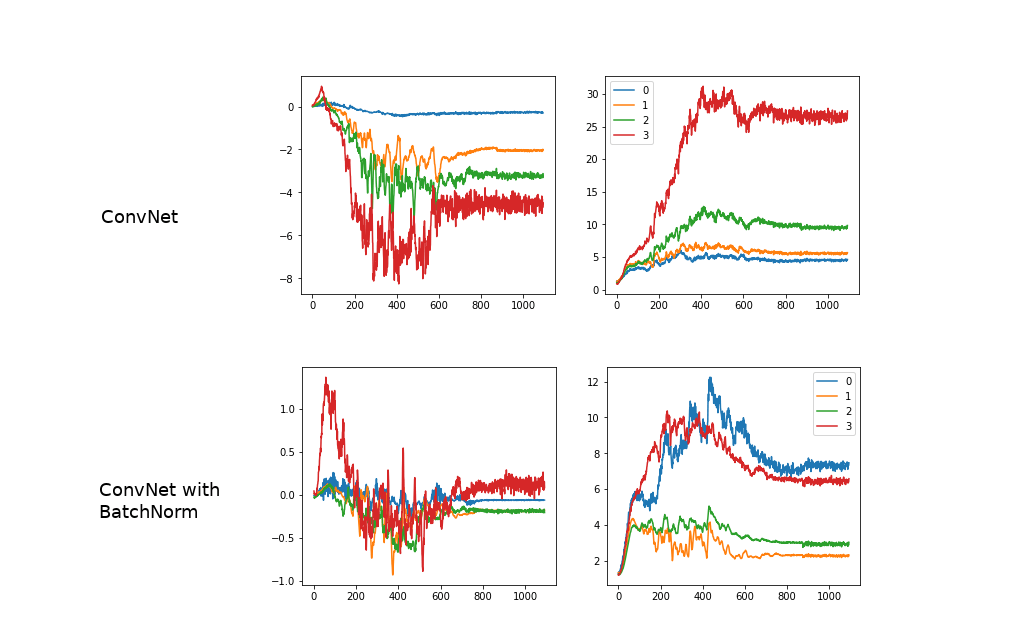
จากใน ep ก่อน ที่เราได้เรียนรู้การทำ Normalization ข้อมูล Input ให้มี Mean=0, Std=1 เท่ากันในทุก Feature ว่ามีประโยชน์ในการเทรน Machine Learning อย่างไร คำถามก็คือ แล้วทำไมเราไม่ทำแบบเดียวกันใน Hidden Layer ของ Deep Neural Network ในขณะที่เราเทรนโมเดล Deep Learning ด้วยล่ะ
สับไพ่ข้อมูล DataLoader ด้วย Random Sampler และ Collate ป้อนโมเดล เทรน Machine Learning – Neural Network ep.7

ในแต่ละ Epoch ของการเทรน Machine Learning สอนโมเดล Deep Neural Network เราไม่ควรป้อนข้อมูลที่เรียงลำดับเหมือนกันทุกครั้งให้โมเดล ใน ep นี้เราจะมาสร้าง DataLoader เวอร์ชันใหม่ ที่จะสับไพ่ข้อมูลตัวอย่างก่อนป้อนให้โมเดล เป็นการลดการจำข้อสอบของโมเดล ช่วยให้โมเดล Generalization ได้ดีขึ้น ลด Variance ของโมเดล
ใช้ Dataset, DataLoader ป้อนข้อมูลให้ Neural Network ทีละ Batch สอน Refactor Training Loop – Neural Network ep.5

ใน ep นี้เราจะมาสร้าง Dataset และ DataLoader เพื่อเป็น Abstraction ในจัดการข้อมูลตัวอย่าง x, y จาก Training Set, Validation Set ที่เราจะป้อนให้กับ Neural Network ใช้เทรน ใน Training Loop ของ Machine Learning