
จาก ep ก่อน ๆ ที่เราได้พูดถึง Activation Function ยอดนิยมอย่าง ReLU ว่าเป็นฟังก์ชันที่ถูกใช้ในโมเดล Deep Learning มากที่สุดในปัจจุบัน แต่เมื่อเวลาผ่านไปมีโมเดลใหม่ ๆ Loss Function ใหม่ ๆ Optimizer ใหม่ ๆ ถูกสร้างขึ้นทุกปี แล้วจะมีฟังก์ชันใหม่อะไรมาแทน ReLU ได้หรือไม่ คำตอบอาจจะเป็น Mish Function
Tag Archives: Vanishing gradient
Layer-Sequential Unit-Variance Initialization (LSUV) คืออะไร แตกต่างกับ Kaiming อย่างไร ในการ Initialize Deep Neural Network – ConvNet ep.6

จากใน ep ก่อน เราได้เรียนรู้การสร้าง ConvNet ขึ้นมาจากหลายส่วนประกอบด้วยกัน และเมื่อสร้างโมเดลขึ้นมาแล้ว ก่อนเทรนเราจำเป็นต้อง Initialize Parameter (Weight, Bias) ต่าง ๆ ด้วยค่าที่เหมาะสม ใน ep ที่แล้ว เราใช้ Kaiming Initalization แล้วถ้าโมเดลเราเกิดซับซ้อนขึ้นเรื่อย ๆ ล่ะ เช่น มีการเปลี่ยน Activaiton Function, มี Skip Connection, มีหลาย Input, เพิ่ม BatchNorm แบบต่าง ๆ, etc. จะทำอย่างไร
ตัวอย่าง Vanishing Gradient Problem และ วิธีแก้ Vanishing Gradient Problem ด้วย Kaiming Initialization – Neural Network ep.3
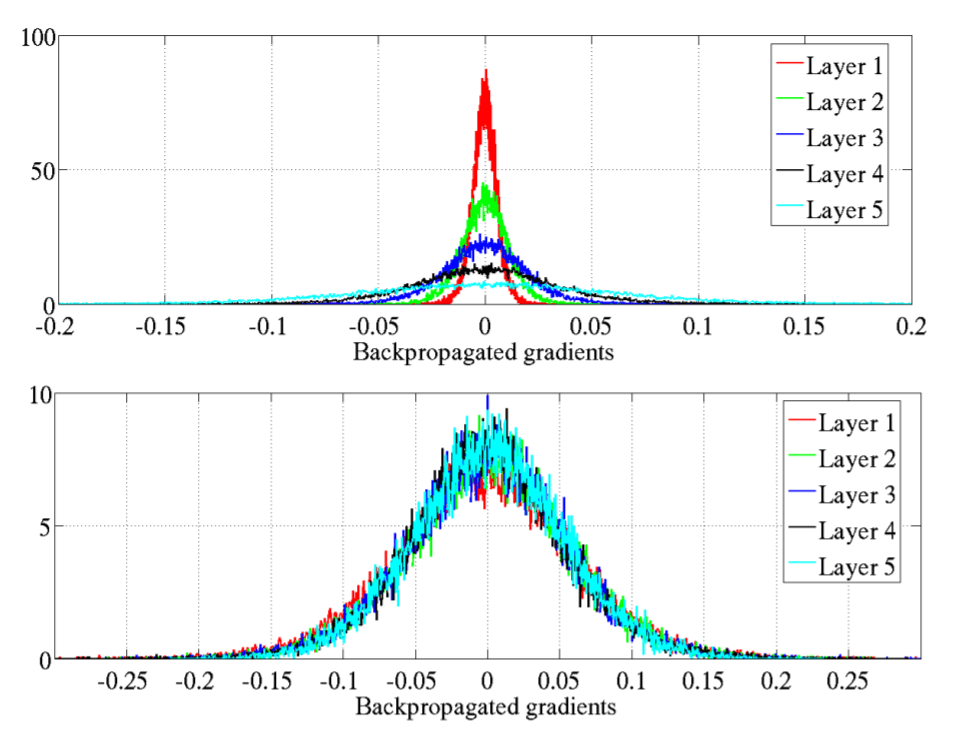
ใน ep ที่แล้วเราได้เรียนรู้ถึงปัญหา Vanishing Gradient Problem และวิธีแก้ไขกันไปแล้ว ใน ep นี้เราจะเจาะลึกลงไปถึงสาเหตุ ดูตัวอย่างของ Neural Network ว่าเมื่อเกิดปัญหา Vanishing Gradient Problem และ Exploding Gradient Problem จะมีอาการอย่างไร และเราจะแก้ไขอย่างไรให้โมเดลสามารถเทรนได้ต่อ
Vanishing Gradient Problem คืออะไร แก้ Vanishing Gradient Problem ด้วย Xavier Initialization และ Kaiming Initialization – Neural Network ep.2
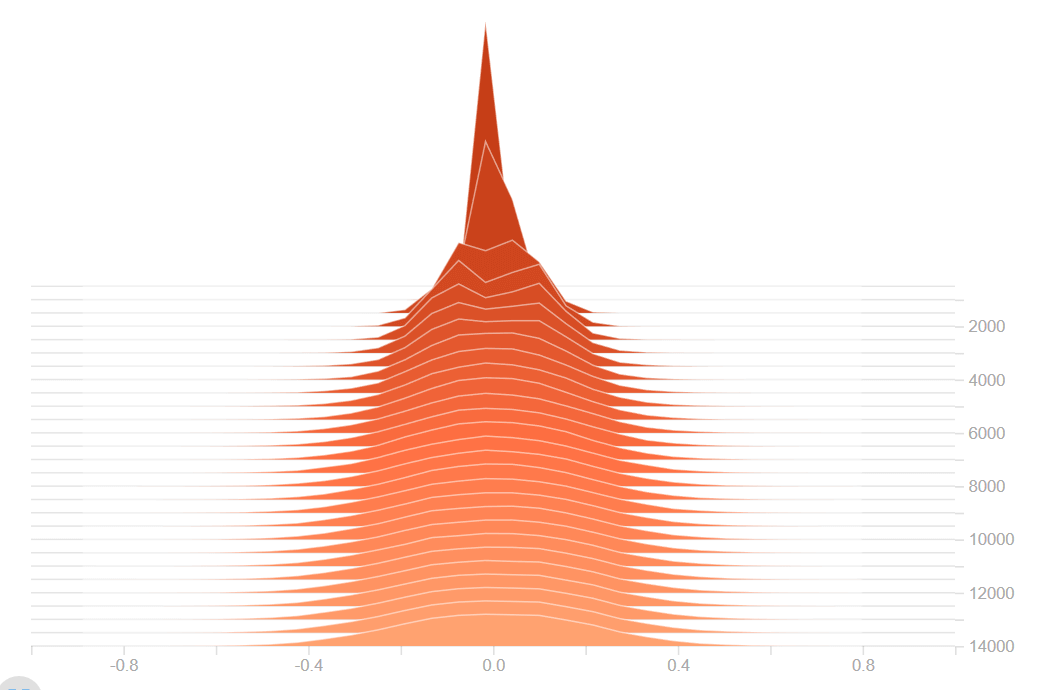
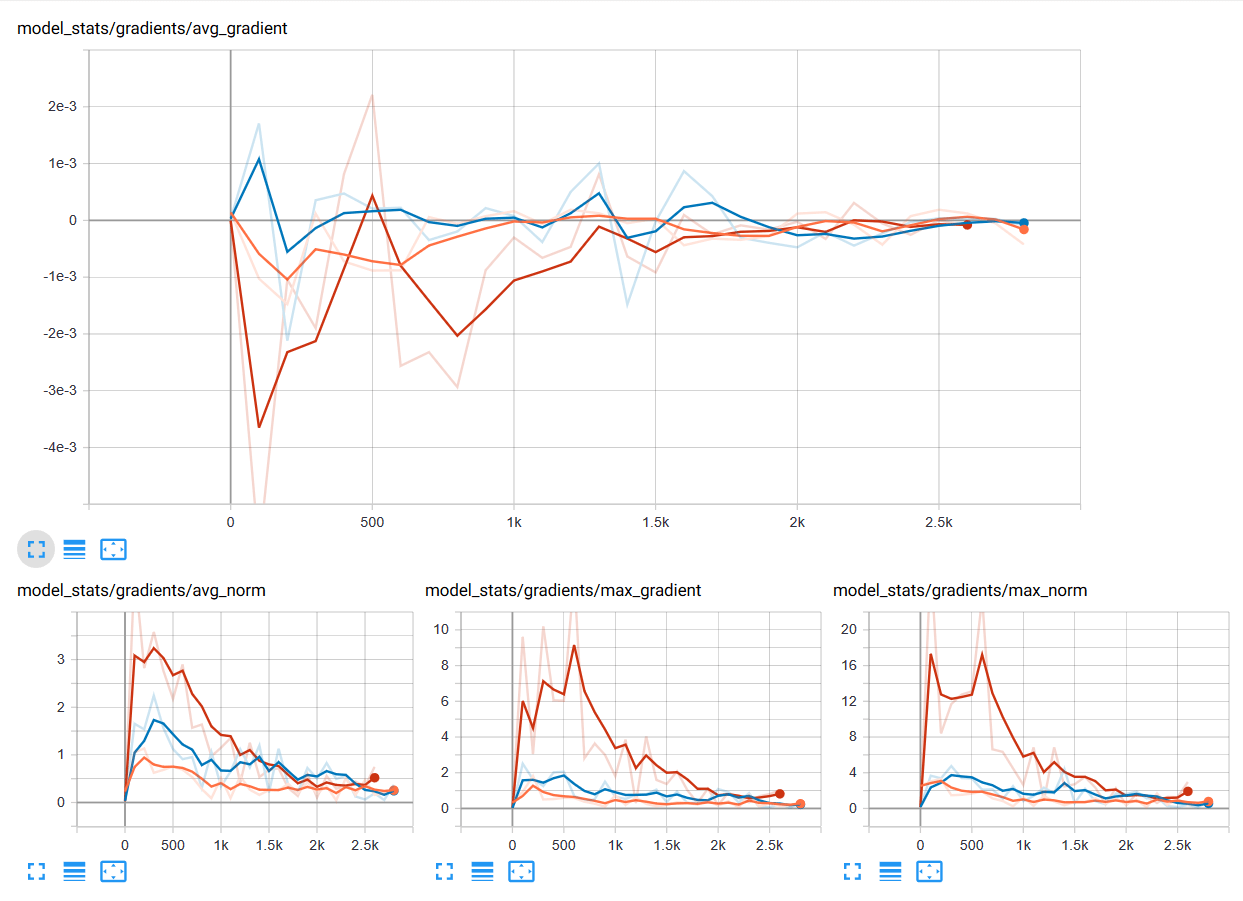
ใน Machine Learning เราจะพบปัญหา Vangishing Gradient ในการเทรน Artificial Neural Network ด้วยอัลกอริทึม Gradient Descent และ Backpropagation ในระหว่างการเทรนโมเดลจะถูกอัพเดท Weight และ Bias จาก Partial Derivative ของ Loss Function ขึ้นกับ Weight, Bias นั้น ๆ ในทุก ๆ รอบการเทรน Vanishing Gradient Problem คือ ปัญหาที่เกิดในบางเคส เราพบว่าในระหว่างการเทรน Gradient มีขนาดเล็กลงเรื่อย ๆ จนเท่ากับ 0 ทำให้ Weight ไม่ถูกอัพเดทอีกต่อไป ทำให้โมเดลเทรนต่อไม่ได้ แล้วเราจะแก้ปัญหานี้อย่างไรดี
ReLU Function คืออะไร ทำไมถึงนิยมใช้ใน Deep Neural Network ต่างกับ Sigmoid อย่างไร – Activation Function ep.3
เรามาถึง Activation Function ep.3 เรื่อง ReLU Function ซึ่งเป็นฟังก์ชันที่นิยมใช้ในการเทรน Deep Learning มากที่สุดในปัจจุบัน เมื่อเราดูโครงสร้างภายในโมเดล Deep Neural Network ชื่อดังสมัยใหม่ ก็จะเห็นแต่ ReLU เต็มไปหมด แล้ว ReLU มีดีตรงไหน ต่างกับ Sigmoid และ Tanh อย่างไร เราจะมาเรียนรู้กัน
Tanh Function คืออะไร เปรียบเทียบกับ Sigmoid Function ต่างกันอย่างไร – Activation Function ep.2
จาก ep ก่อนที่เราเรียนรู้เรื่อง Activation Function คืออะไร ใน Artificial Neural Network และพูดถึง Sigmoid Function แต่ในปัจจุบัน Activation Function ที่ได้รับความนิยมมีอีกหลายตัว หนึ่งในนั้นคือ Tanh แล้ว Tanh ต่างกับ Sigmoid อย่างไร ทำไมถึงต้องมี Tanh ขึ้นมาอีก
Activation Function คืออะไร ใน Artificial Neural Network, Sigmoid Function คืออะไร – Activation Function ep.1
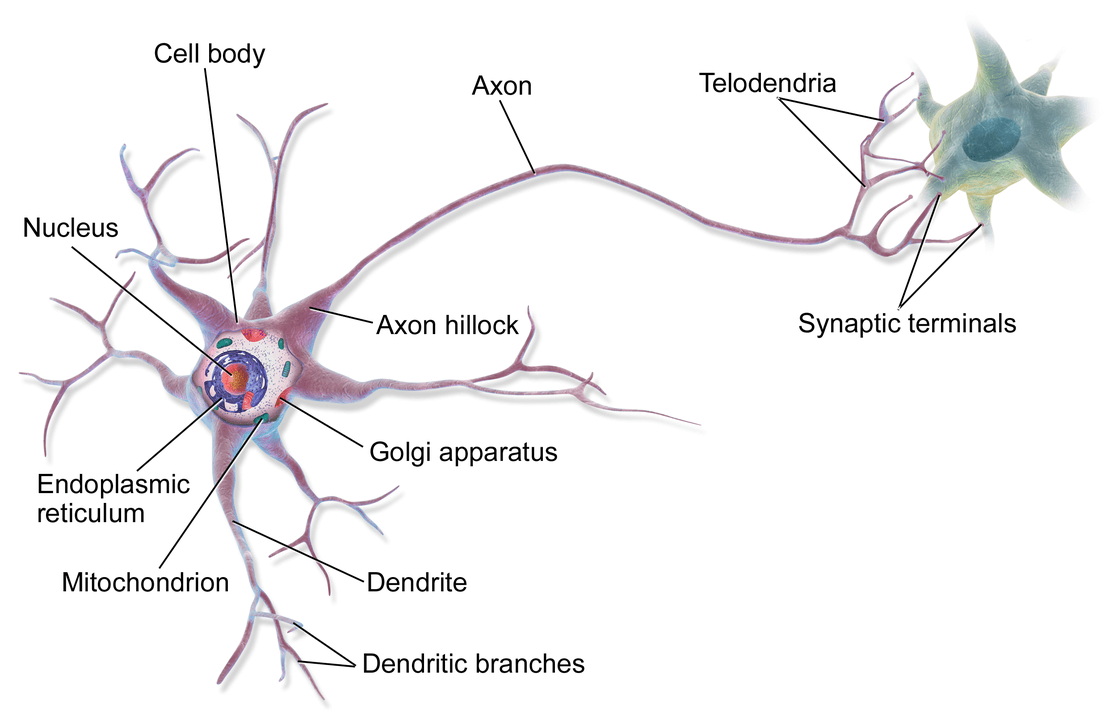
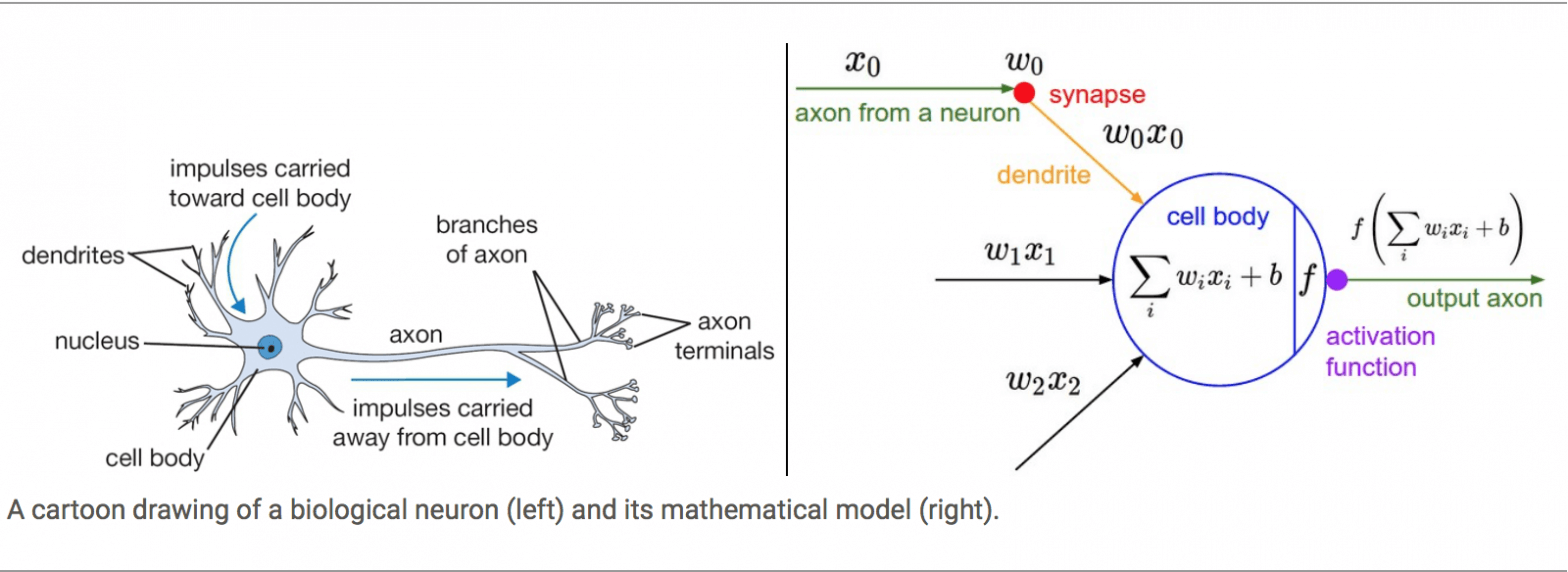
ในสมองของมนุษย์คนหนึ่ง จะประกอบด้วยหน่วยเล็ก ๆ เรียกว่า นิวรอน (Neuron) จำนวนประมาณ 8 หมื่น 6 พันล้านนิวรอน ดังรูปด้านบน และแต่ละนิวรอนก็จะเชื่อมต่อโยงใยกันด้วยเส้นประสาทเรียกว่า ไซแนปส์ (Synapse) รวมแล้วประมาณ 1 พันล้านล้านไซแนปส์ ซึ่งนักวิทยาศาสตร์คอมพิวเตอร์ได้นำมาเป็นแนวคิดในการออกแบบ Artificial Neural Network