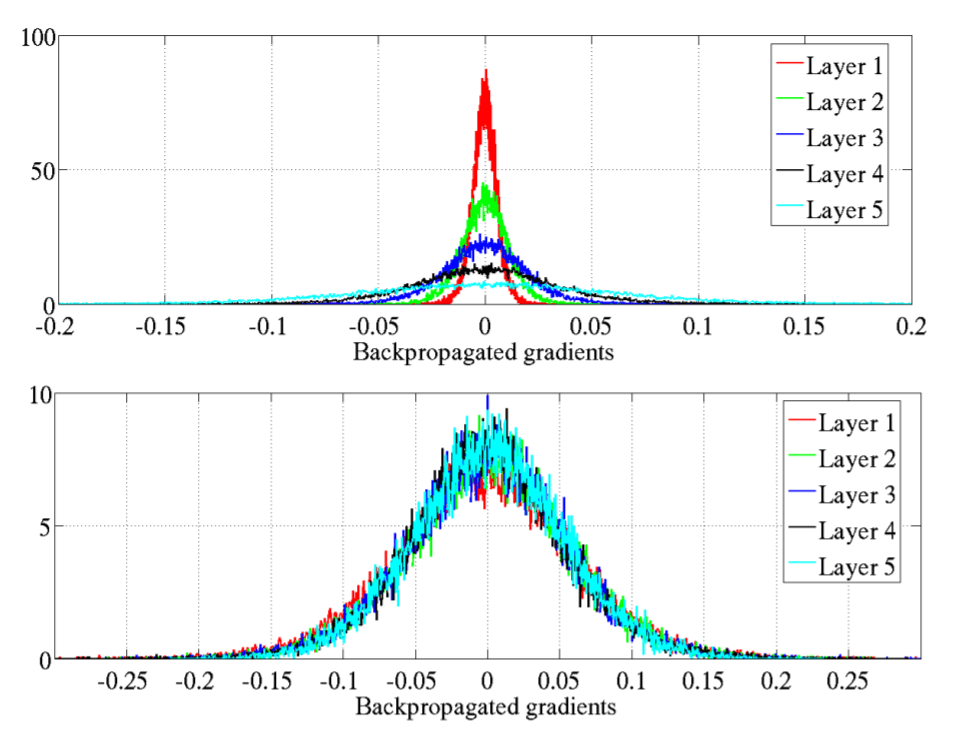
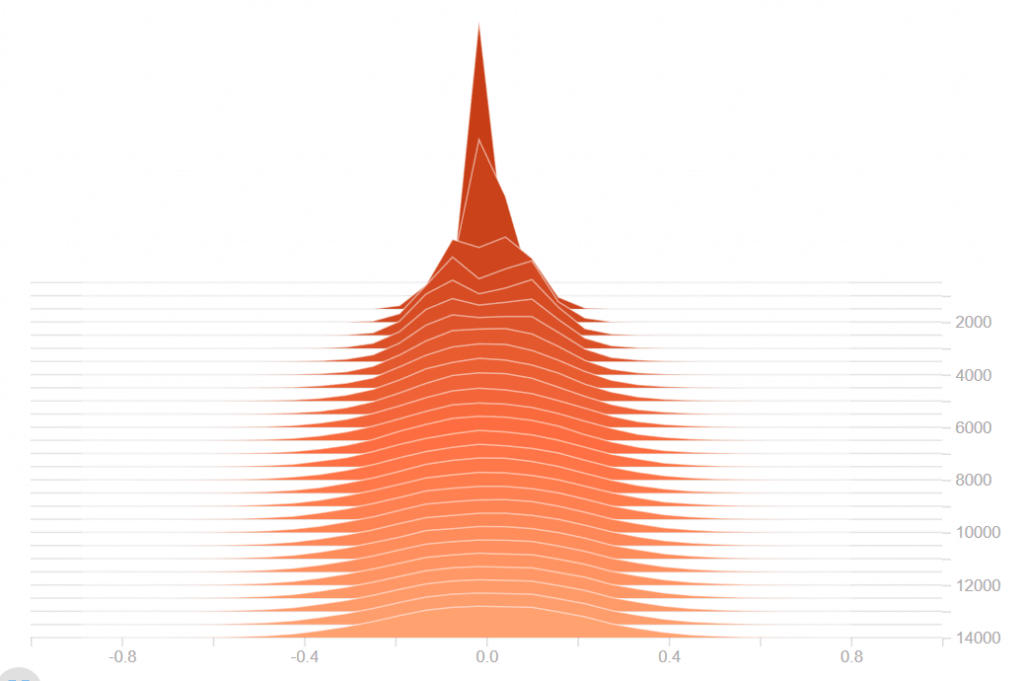
ใน ep ที่แล้วเราได้เรียนรู้ถึงปัญหา Vanishing Gradient Problem และวิธีแก้ไขกันไปแล้ว ใน ep นี้เราจะเจาะลึกลงไปถึงสาเหตุ ดูตัวอย่างของ Neural Network ว่าเมื่อเกิดปัญหา Vanishing Gradient Problem และ Exploding Gradient Problem จะมีอาการอย่างไร และเราจะแก้ไขอย่างไรให้โมเดลสามารถเทรนได้ต่อ
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

