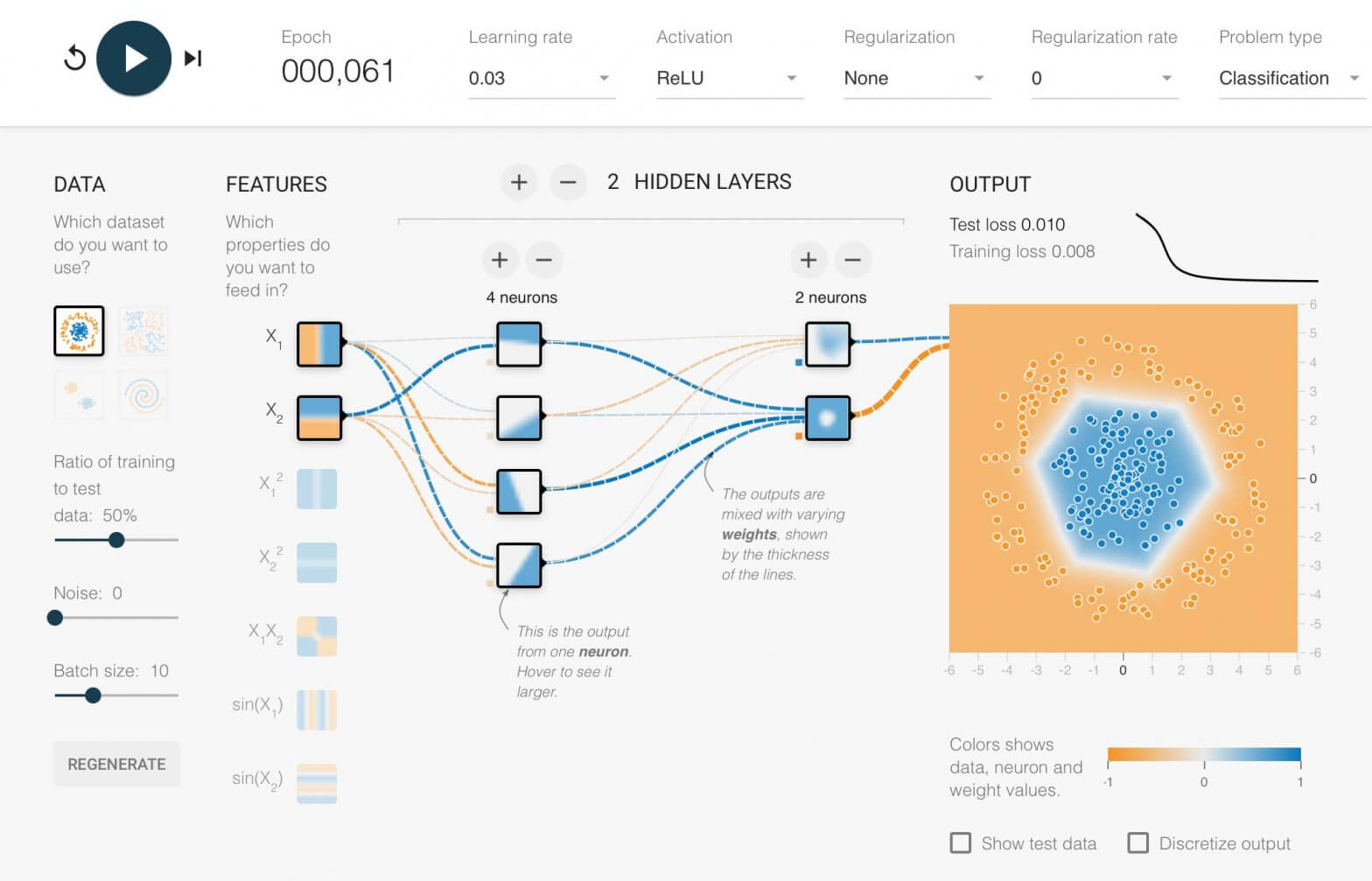
Neural Network หรือ Artificial Neural Network คือ โครงข่ายประสาทเทียม เป็นสาขาหนึ่งของปัญญาประดิษฐ์ Artificial Intelligence (AI) เป็นแนวคิดที่ออกแบบระบบโครงข่ายคอมพิวเตอร์ ให้เลียนแบบการทำงานของสมองมนุษย์
ใน ep นี้เราจะมาดูกันว่า ภายใน Neural Network นั้นทำงานอย่างไร และเราจะมาสร้าง 2 Layers Deep Neural Network กันตั้งแต่ Tensor, Matrix และฟังก์ชันคณิตศาสตร์พื้นฐาน บวก ลบ คูณ หาร แบบเข้าใจง่าย ๆ ไปทีละขั้นด้วยกัน
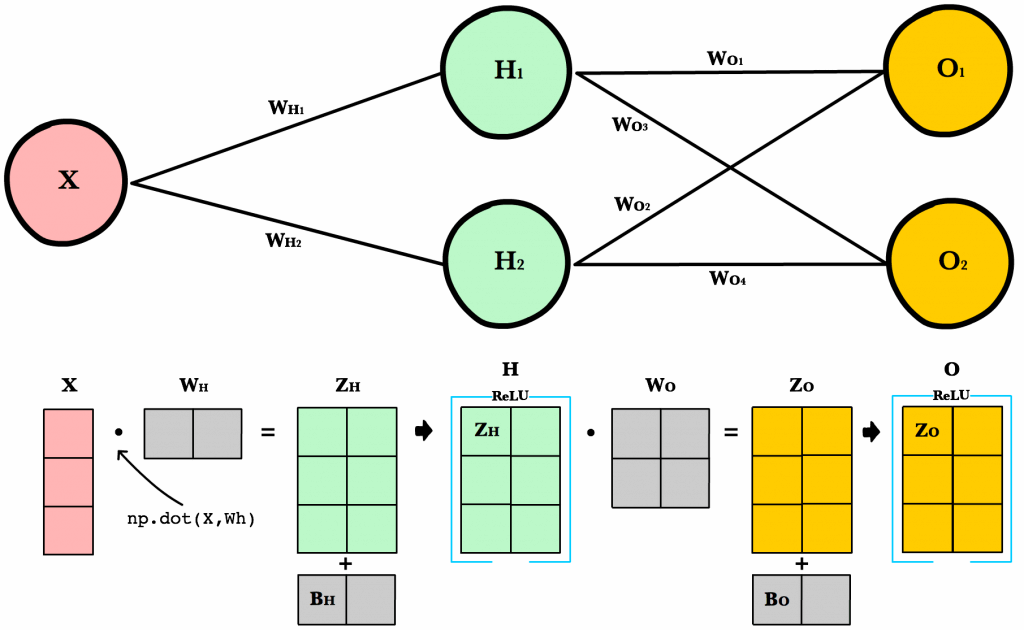
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

