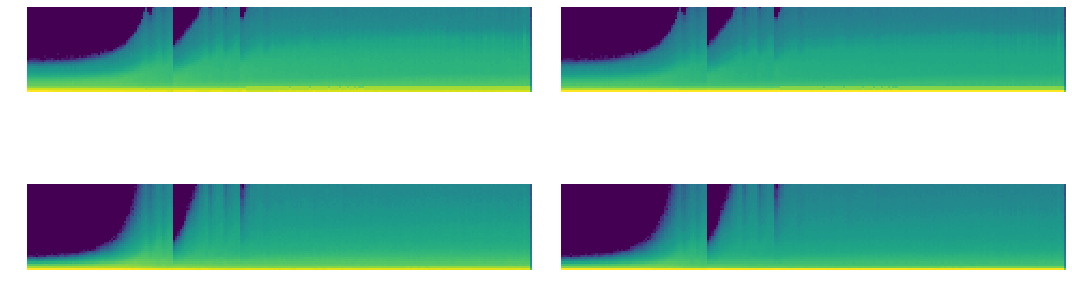
จากใน ep ที่แล้วเราได้เรียนรู้การใช้งาน PyTorch Hook ใน ep นี้เราจะมา Refactor โค้ดสร้าง Class ขึ้นมาจัดการ Hook และใช้ Hook สถิติ ที่ลึกมากขึ้น
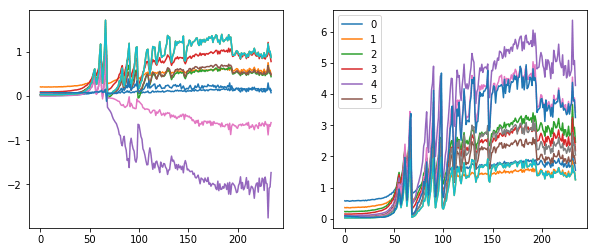
เราจะวิเคราะห์กราฟ Mean, Std และ Histogram จะเห็นว่าค่อนข้าง Converge เร็ว ไม่เกิด Vanishing Gradient เนื่องจาก PyTorch ได้แก้ปัญหาไปแล้วด้วย Kaiming Initialization แต่ก็ยังมีปัญหาอื่น ๆ อยู่ในช่วงแรก ๆ แล้วเราจะแก้ปัญหานี้อย่างไร
GeneralReLU คืออะไร
เราจะแก้ปัญหานี้ ด้วย ReLU แบบใหม่ ที่ลดความไม่ Balance เนื่องจากค่าลบหายไปหมด, มีการ Cap Activation ไม่ให้เกินค่าที่กำหนด และมีการใช้ Leaky ReLU ในส่วนที่ติดลบด้วย
รวมเรียกว่า GeneralReLU เราจะเปลี่ยน ReLU Activation Function ใน Convolutaional Neural Network ของเราเป็น GeneralReLU ทั้งหมด เพื่อให้เทรนโมเดลให้ Converge ได้เร็วขึ้น เราจะเริ่มต้นที่หัวข้อ 6.2 Hook
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

