ใน ep ที่แล้ว Neural Network ep.13 ที่เราได้สร้างโมเดล Deep Neural Network ที่ใช้ Linear Layer + ReLU Activation Function เราได้สร้าง Training Loop ที่มีความ Flexible จาก Callback ทำให้เราสามารถ Schedule Hyperparameter ได้ตามต้องการ
แต่ไม่ว่าจะเทรนอย่างไร เราก็จำแนก MNIST ได้ Accuracy สูงสุดแค่ 97% เท่านั้น เนื่องจากข้อจำกัดของ Model Architecture แล้วเราจะแก้ปัญหานี้อย่างไรดี
Convolutional Neural Network คืออะไร
Convolutional Neural Network คือ Neural Network แบบหนึ่งที่มักถูกนำมาใช้ในงาน Computer Vision หรือ วิเคราะห์รูปภาพ เช่น Image Classification จำแนกรูปภาพ, Object Detection ตรวจจับวัตถุ, Face Recognition เรียนรู้จดจำใบหน้า, etc.
Convolutional Neural Network ทำงานอย่างไร
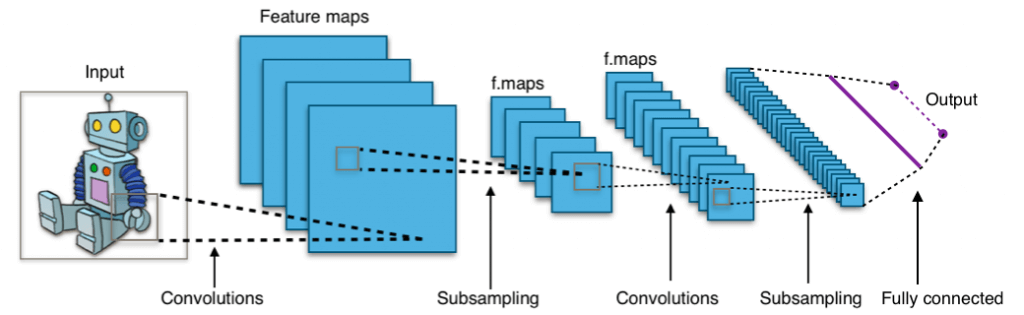
Convolutional Neural Network คือ Deep Learning อัลกอริทึม ที่จะรับ Input เป็นรูปภาพ แล้วเรียนรู้ Feature ต่าง ๆ ของรูปภาพเหล่านั้น ในแต่ละ Layer ต่อยอดขึ้นไปเรื่อย ๆ ตั้งแต่ จุด, เส้นแนวตั้ง, เส้นแนวนอน, เส้นแนวทแยง, กากบาท, มุม, เส้นโค้ง, วงกลม, พื้นผิว, ลวดลาย, ดวงตา, ใบหน้า, … ไปจนถึง วัตถุที่เรากำหนด
Input Image
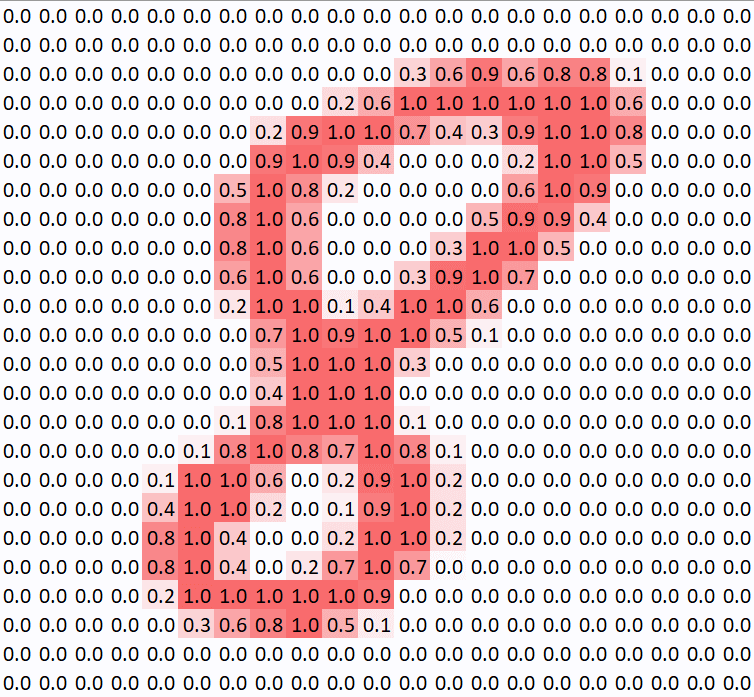
รูปภาพที่อยู่ในคอมพิวเตอร์ ในกรณีรูปขาวดำ ก็คือ ข้อมูลตัวเลขความสว่าง 0-255 ที่นำมาจัดเรียงเป็น Matrix กว้าง x ยาว (Width x Height) จากตัวอย่าง MNIST ด้านบน ถ้าเป็นรูปสี ก็จะเป็น 3 Channel RGB กว้าง x ยาว x ลึก (Widgh x Height x Depth)
ConvLayer – Kernel/Filter
Convolution Layer (ConvLayer) คือ Layer ที่อยู่แรก ๆ ของโมเดล CNN, ConvLayer ทำหน้าที่สกัดเอา Feature สำคัญ จากรูปภาพ, ConvLayer มีความพิเศษตรงที่ คงความสัมพันธ์ของ Pixel ที่อยู่บริเวณพื้นที่ใกล้เคียงกันเอาไว้ด้วย
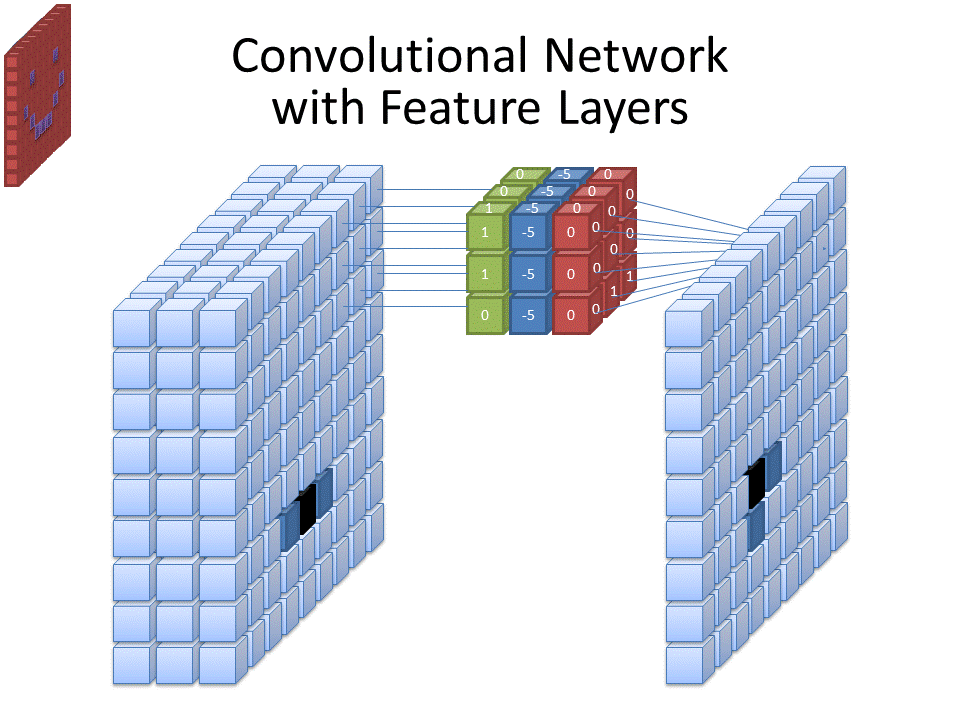
เปรียบเทียบกับการทำงานของ Neural Network ธรรมดาที่เชื่อมทุก ๆ Neuron ของ Layer ก่อนหน้าเข้าด้วยกัน แต่ ConvLayer เลือกที่จะเชื่อมแค่บริเวณที่ต้องการ เรียกว่า Receptive Field
การทำ Convolution รูปด้วย Filter ที่แตกต่างกัน จะได้ความหมายที่แตกต่างกันไป เช่น หาขอบรูป, หาความเบลอ, หาความคม เริ่มต้นที่ Layer แรก เส้นตรง เส้นโค้ง ไปถึง Layer หลัง ๆ ก็จะนามธรรม (Abstract) ขึ้นเรื่อย ๆ
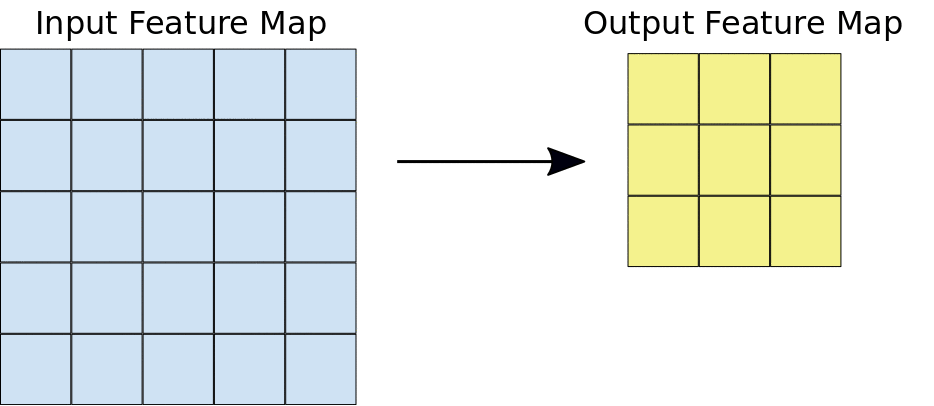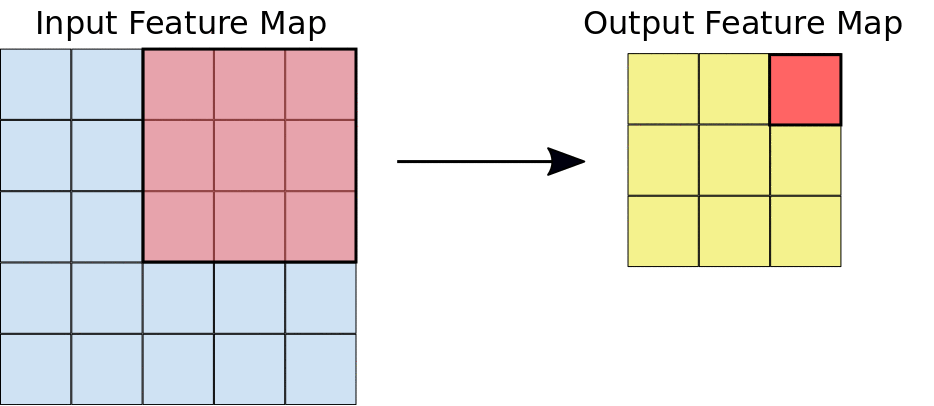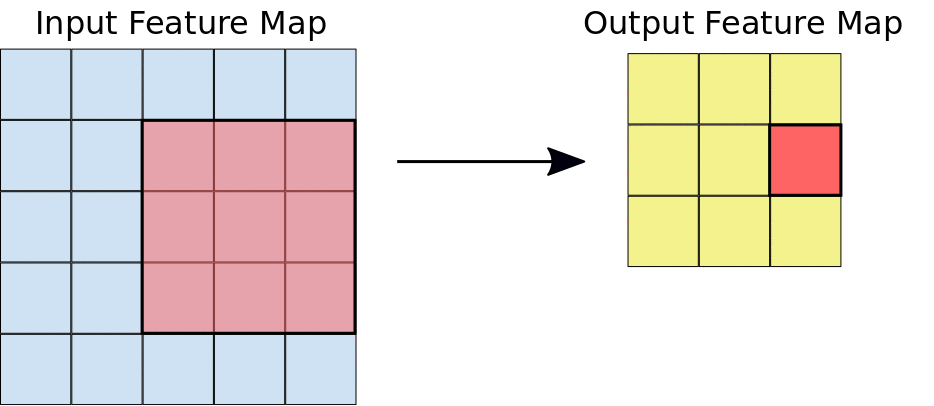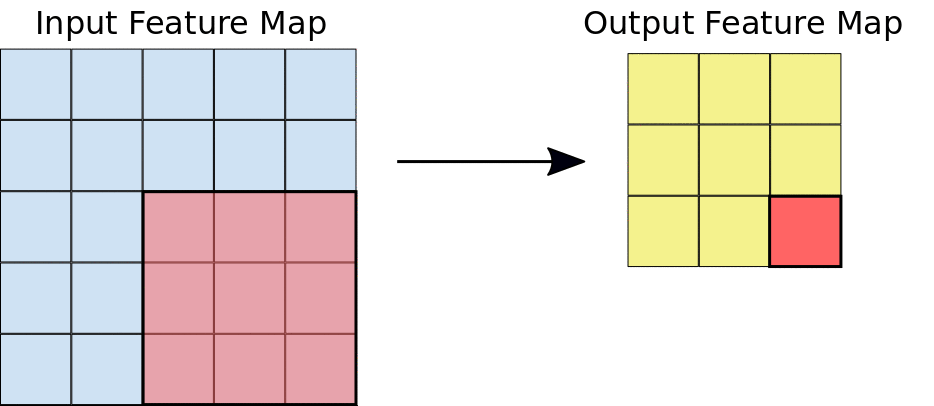
Filter (สีชมพู) จะมีขนาดเท่าไร (Kernel Size) วิ่งทีละกี่ช่อง (Stride) เป็น Hyperparameter ที่เราต้องกำหนด ในแต่ละ Layer
Filter หน้าตาเป็นอย่างไร เป็น Parameter ที่โมเดลจะต้องเรียนรู้ ส่วน Output ของการ Convolution (สีเขียว) เรียกว่า Activation Map หรือ Feature Map
Receptive Field
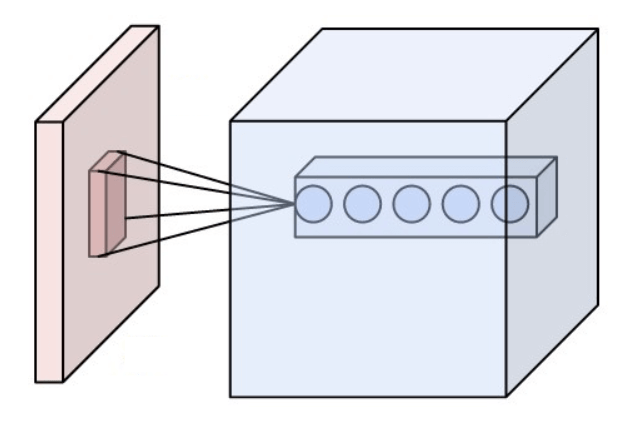
สถาปัตยกรรม Model Architecture ของ ConvNet ได้แรงบันดาลใจมาจาก ระบบประสาทการมองเห็น Visual Cortex ในสมองของมนุษย์ แต่ละ Neuron จะรับผิดชอบพื้นที่จำกัดของตัวเอง เรียกว่า Receptive Field โดยที่หลาย ๆ Neuron ใกล้เคียงกันจะช่วยกันดูแลพื้นที่ใกล้เคียงคาบเกี่ยวกัน จนครอบคลุมหมดทั้งพื้นที่
Custom Head
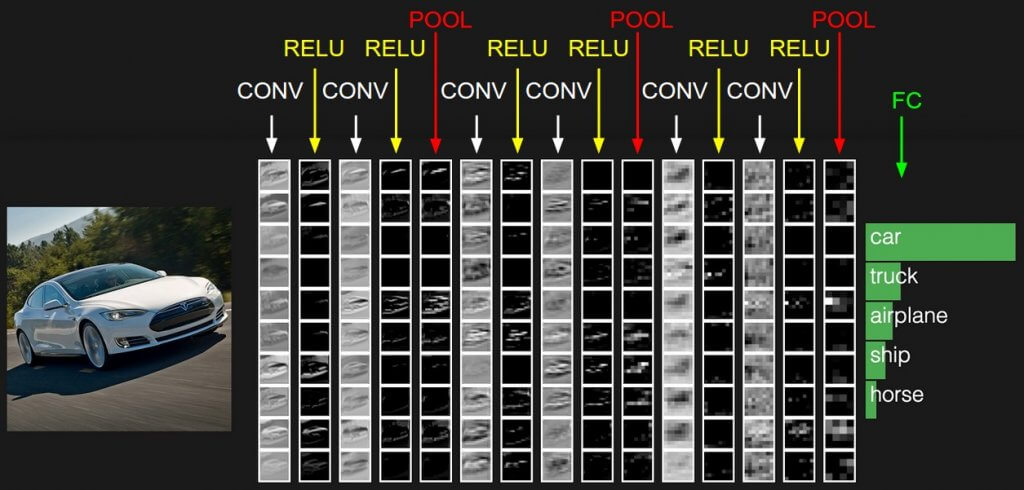
หลังจากที่ผ่านหลาย ๆ Convolutional Layer มา โมเดลส่วนใหญ่จะจบด้วย Fully Connected Layer เพื่อปรับ Output ของโมเดลให้ออกมาตรงกับงานที่เราต้องการ เช่น Classification 10 Class เราก็จะใช้ Fully Connected Layer ที่มี Input = Output ของ ConvLayer ท้ายสุด Flatten, Output = 10 แล้วต่อด้วย Softmax หรือ Sigmoid Activation Function
เรามาเริ่มกันเลยดีกว่า
ดังนั้นใน ep นี้เราจะปรับ Model Architecture จาก Linear Layer ธรรมดา กลายเป็น Conv2d Layer ทำให้โมเดลของเรากลายเป็น Convolutional Neural Network (CNN) ซึ่งเป็น Neural Network ชนิดหนึ่ง ที่เหมาะงาน Computer Vision
การเลือกว่าจะใช้ Model Architecture ไหน ก็ถือเป็น Hyperparameter เช่นกัน เราจะเริ่มต้นที่หัวข้อ 4. Model
![]()
![]()

