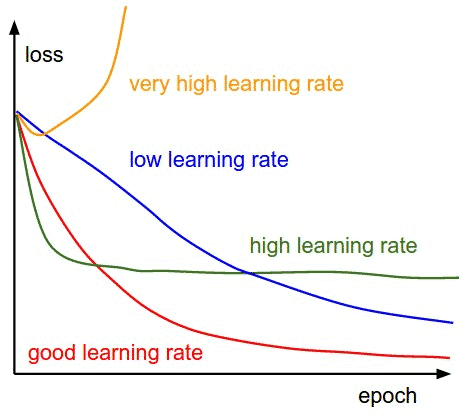
ใน ep นี้เราจะมาเรียนรู้กันว่า Learning Rate คืออะไร Learning Rate สำคัญอย่างไรกับการเทรน Machine Learning โมเดล Neural Network / Deep Learning เราจะปรับ Learning Rate อย่างไรให้เหมาะสม เราสามารถเทรนไปปรับไปได้ไหม หรือต้องใช้ค่าคงที่ตลอด และโมเดลที่ Transfer Learning กับโมเดลที่เทรนใหม่เลย ต้องการ Learning Rate, จำนวน Epoch ต่างกันอย่างไร
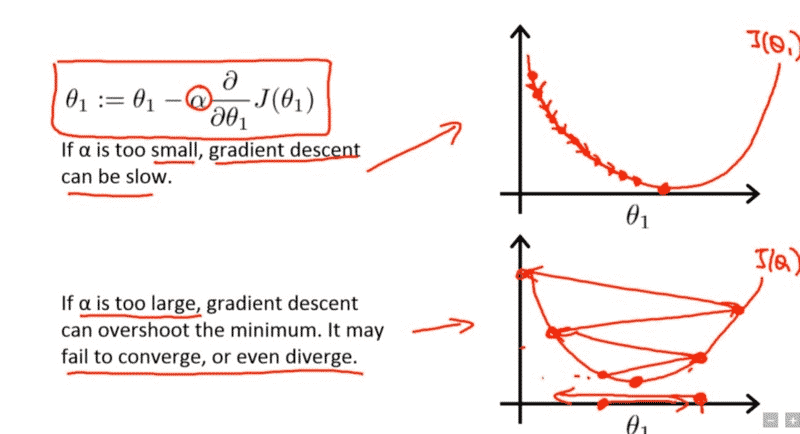
ในการเทรนโมเดล Deep Learning เราต้องเข้าใจก่อนว่าอัลกอริทึมที่ใช้ในการเทรน ที่ชื่อว่า Gradient Descent ทำงานอย่างไร และ Hyperparameter หลักในการควบคุมการทำงานของ Gradient Descent ก็คือ Learning Rate
Learning Rate คืออะไร
Learning Rate คือ Hyperparameter ตัวหนึ่งที่ควบคุมว่าในหนึ่ง Step ของการเทรน เราจะปรับ Weight ของ Neural Network มากน้อยแค่ไหน
- ถ้า Learning Rate มีค่าน้อย Weight ของโมเดลก็จะเปลี่ยนแปลงน้อย การทำงานของโมเดลก็จะเปลี่ยนไปน้อย Loss ก็ไม่ค่อยเปลี่ยนเท่าไร
- ถ้า Learning Rate มีค่ามาก Weight ของโมเดลก็จะเปลี่ยนแปลงมาก การทำงานของโมเดลก็จะเปลี่ยนไปมาก Loss ก็จะเปลี่ยนแปลงมาก
เรามาเริ่มกันเลยดีกว่า
หมายเหตุ
- ในกรณีนี้เราถือว่า Bias คือ Weight ตัวที่ 0 ที่คุณกับ x0 (ที่ค่าเป็น 1 เสมอ) จึงถือว่า Bias เป็น Weight เหมือนกัน เราจะไม่ได้เขียนแยก ว่า Weight และ Bias
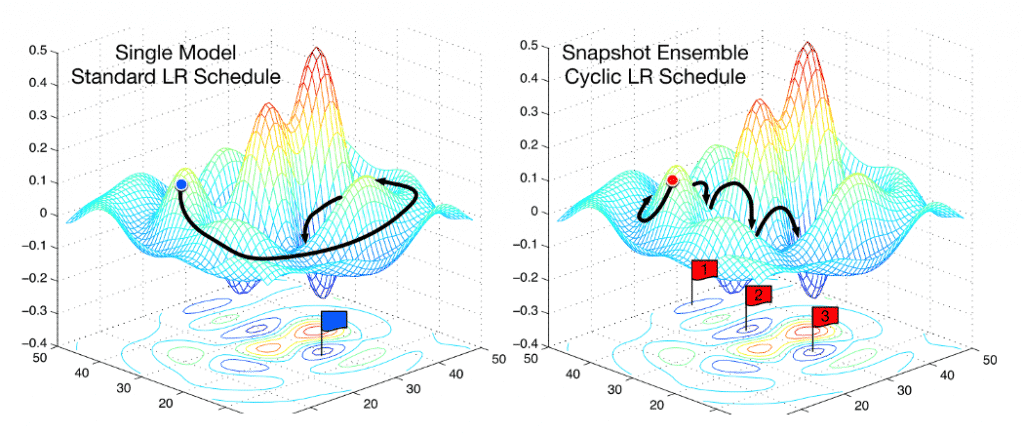
Learning Rate แบบไม่คงที่
Learning Rate ไม่จำเป็นต้องคงทีตลอดการเทรน ปัจจุบันมี Paper มากมาย นำเสนอไอเดียการเพิ่มลด Learning Rate ระหว่างเทรน เช่น
- ค่อย ๆ ลด Learning Rate ไปเรื่อย ๆ ทุก Epoch
- แบ่งการเทรนเป็น N Cycle แล้วเพิ่ม Learning Rate จนสุด Max ลดจนถึง Min ทุก Cycle เป็นฟันปลา
- รวม 2 แบบบนเข้าด้วยกัน เทรน N Cycle โดยลดค่า Max Learning Rate ทุก Epoch
- Stochastic Gradient Descent with Warm Restarts ค่อย ๆ เพิ่ม/ลด Learning Rate ด้วย Cosine Function โค้ง ๆ แทนที่จะเป็นฟันปลา
- etc.
เชื่อว่า การเพิ่ม/ลด Learning Rate นี้จะช่วยให้ เราเทรนโมเดลได้รวดเร็วขึ้น โมเดลสามารถกระโดดข้ามภูเขา และกระโดดออกมาจาก หลุม Local Minima ได้ ซึ่งเราจะอธิบายต่อไป
Learning Rate สำหรับ Pretrained Model
จากบทความเรื่อง Image Classification เรามีการใช้ Transfer Learning จากโมเดล Resnet34 ตัด Layer สุดท้ายทิ้ง เทรนเฉพาะ Layer สุดท้าย ด้วย Learning Rate ที่สูง unfreeze แล้วเทรนทั้งโมเดล ด้วย Learning Rate ที่ต่ำลง และแบ่งเป็นช่วง ๆ สาเหตุเพราะว่า Layer ต่างกัน ต้องการความเปลี่ยนแปลง ของ Weight หรือ Learning Rate ที่ต่างกัน
เช่น ใน Convolution Neural Network (CNN) Layer แรก จะเป็นเรื่องพื้นฐาน เช่น เส้นตั้ง เส้นนอน เส้นทแยง Layer ต่อมาจะเป็นมุม เป็นเส้นโค้ง เป็นเรื่องที่ไม่ว่ารูปแบบไหนก็ต้องประกอบขึ้นมาจากส่วนประกอบพื้นฐานเหล่านี้ Layer เหล่านี้ต้องการ Learning Rate ที่ต่ำมาก ตรงข้ามกับ Layer หลัง ๆ ซึ่งเกี่ยวกับ Object, ดวงตา, ใบหน้า, พื้นผิว Texture, ตัวหนังสือ ที่เราต้องการ Tune ให้เข้ากับงานที่เรา ซึ่งต้องการ Learning Rate ที่สูงกว่า
ใน learner.fit_one_cycle เราจึงมีการกำหนด Maximum Learning Rate (max_lr) ด้วย split(3e-6, 3e-3) เพื่อให้ Layer แรก ๆ ได้ค่า Learning Rate น้อย ๆ คือ 3e-6 ไล่ไปจนถึง Layer สุดท้าย ได้ค่า Learning Rate มากที่สุด คือ 3-e3
Credit
- https://towardsdatascience.com/understanding-learning-rates-and-how-it-improves-performance-in-deep-learning-d0d4059c1c10
- https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
- https://machinelearningmastery.com/learning-rate-for-deep-learning-neural-networks/
- Cover Image: http://cs231n.github.io/neural-networks-3/
- https://course.fast.ai/videos/?lesson=2
- https://www.coursera.org/learn/machine-learning

