
ในการเทรน Artificial Neural Network เราต้องการทราบว่าการเปลี่ยนแปลงขยับ เพิ่ม/ลด Weight หนึ่ง ๆ มีผลต่อการ เพิ่ม/ลด Loss อย่างไร โดยสมมติว่า Weight อื่น ๆ คงที่ทั้งหมด เช่นถ้าเราเพิ่ม Weight A + 0.0001 แล้ว Loss ลด เราก็ลองเพิ่ม Weight A ไป แล้วลองเทสดู ทำแบบนี้ไปทุก Weight ซ้ำไปเรื่อย ๆ จนกว่าจะได้ Loss ที่น้อยที่สุด
ในทางคณิตศาสต์ เราไม่ต้องมาค่อย ๆ ขยับเช็คทีละ Weight เราสามาถใช้ Calculus ทำการ Diff สมการ หา Derivative ความชัน Slope ของ Weight/Loss ออกมาได้เลยว่า Loss จะเพิ่มเท่าไร เมื่อเราขยับ Weight เท่าไร Gradient Descent หมายถึงเราจะค่อย ๆ ขยับ ทุก ๆ Weight ไปทางที่ Slope ติดลบ ไปเรื่อย ๆ ให้ได้ Loss ต่ำที่สุด
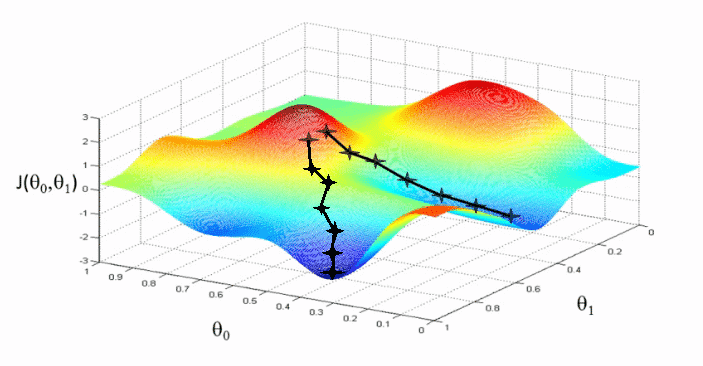
ดังตัวอย่างจากคอร์ส Machine Learning ของ Andrew Ng ยกตัวอย่าง ฟังก์ชัน J( θ0, θ1) แกน Z ที่มี Weight 2 ตัวคือ θ0 แกน X และ θ1 แกน Y เราควรจะเพิ่มลด θ0, θ1 อย่างไร ให้เราเคลื่อนจากจุดสูงสีแดง ขยับซ้าย/ขวา/หน้า/หลัง อย่างไร ให้ไปยังสู่จุดที่ตำที่สุดของกราฟสีน้ำเงิน
ในการเทรน Deep Learning ทีมี Weight หลายล้านตัว วิธีที่จะหาว่า Slope มีค่าเท่าไร ที่นิยมในปัจจุบันจะใช้ Multivariate Calculus หา Diff ความชันของ Slope ทีเดียวทุก Weight ไปเลย โดยจะหาทีละ Layer จากหลังมาหน้า เรียกว่า Backpropagation ที่เราจะอธิบายต่อไป
ในการเทรนโมเดล ตอนท้ายเมื่อเราได้ Gradient ของทุก Weight ใน Model มาแล้ว เราก็จะมา Update Weight กันด้วย โค้ดดังนี้ แล้วจึงเริ่มเทรนรอบใหม่
w = w - (lr * w.grad)- w คือ Weight ที่เรากำลังจะอัพเดท
- lr คือ Learning Rate
- – ลบ เนื่องจากเราต้องการ ไปตรงข้ามกับ Slope
- w.grad คือ Gradient หรือ Slope ของ w นั้น ต่อ Loss
วิธีนี้เรียกว่า Stochastic Gradient Descent (SGD) เป็นวิธีเรียบง่ายที่สุด คือ Gradient เอามาคูณ Learning Rate แล้วลบตรง ๆ เลย แต่ในปัจจุบันวิธีการอัพเดท Weight ที่นิยมมีอีกหลายวิธี เช่น Momentum, RMSProp, AdaGrad, Adam, etc. ที่เราจะอธิบายต่อไป
Learning Rate (lr)
เนื่องจากเรามี Weight หลายล้านตัวในโมเดล จะเห็นได้ว่า Learning Rate จะเป็นตัวคูณว่าจะ หักค่าเหล่านั้น ด้วยกี่เท่าของ Gradient ของตัวมันเอง เช่น ถ้า lr = 0.5, w ก็จะถูกลบไป 0.5 w.grad ดังนั้น Learning Rate จึงเป็นตัวคุมการอัพเดท Weight ทั้งหมด มีความสำคัญ และเป็น Hyperparameter หลักในการเทรนโมเดล ดังที่เราจะอธิบายต่อไป

