ใน Machine Learning เราจะพบปัญหา Vangishing Gradient ในการเทรน Artificial Neural Network ด้วยอัลกอริทึม Gradient Descent และ Backpropagation ในระหว่างการเทรนโมเดลจะถูกอัพเดท Weight และ Bias จาก Partial Derivative ของ Loss Function ขึ้นกับ Weight, Bias นั้น ๆ ในทุก ๆ รอบการเทรน
Vanishing Gradient Problem คือ ปัญหาที่เกิดในบางเคส เราพบว่าในระหว่างการเทรน Gradient มีขนาดเล็กลงเรื่อย ๆ จนเท่ากับ 0 ทำให้ Weight ไม่ถูกอัพเดทอีกต่อไป ทำให้โมเดลเทรนต่อไม่ได้ แล้วเราจะแก้ปัญหานี้อย่างไรดี
Exploding Gradient Problem คือ ปัญหาตรงข้ามกับ Vanishing Gradient Problem เราพบว่าในระหว่างการเทรน Gradient มีขนาดใหญ่ขึ้นเรื่อย ๆ จนเท่ากับ Infinity หรือ Not a Number (NaN) หมายถึง ตัวเลขเกินที่ระบบจะรับไหว ทำให้โมเดลเทรนต่อไม่ได้ ต้อง Reset โมเดล แล้วเริ่มเทรนใหม่
การแก้ปัญหา Vanishing Gradient Problem
เราสามารถแก้ปัญหา Vanishing Gradient Problem และ Exploding Gradient Problem ได้ด้วยหลายวิธี ดังนี้
- Weight Initialization
- Batch Normalization
- ใช้ Long Short Term Memory แทน Vanilla RNN
- Residual Networks
- ใช้ ReLU แทน Sigmoid Activation Function
ใน ep นี้เราจะมาเรียนรู้เรื่อง Weight Initialization แบบต่าง ๆ ที่จะมาช่วยแก้ปัญหา Vanishing Gradient Problem และ Exploding Gradient Problem
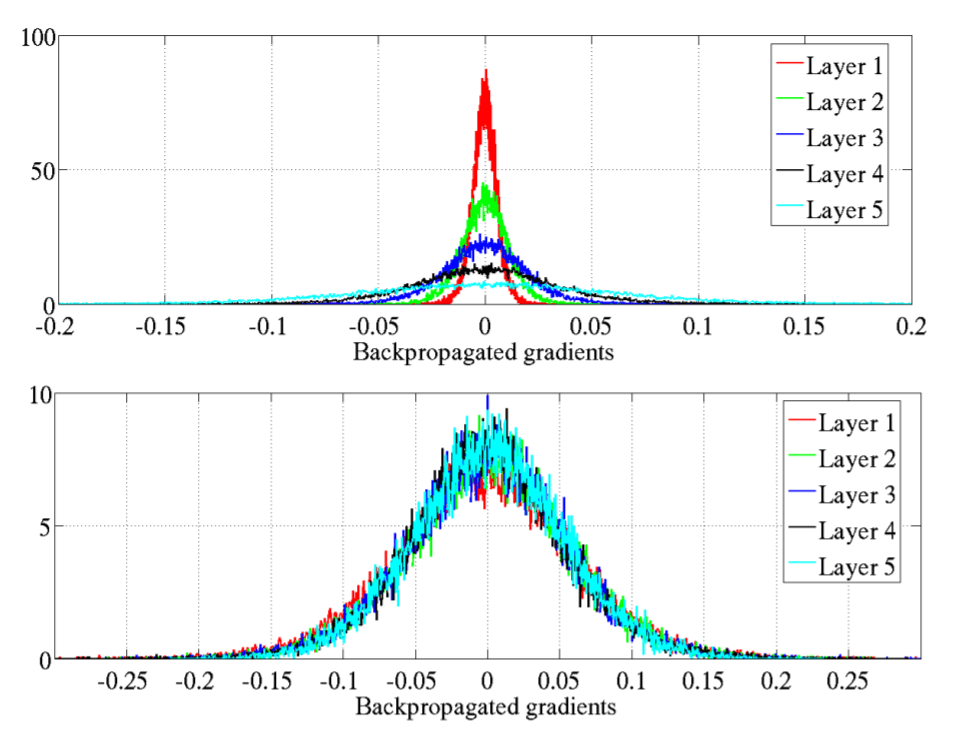
กราฟบนคือ Neural Network ที่ Weight ที่ไม่ได้ถูก Initialize แบบ Normalized สังเกตว่า Gradient จะหายไปเรื่อย ๆ ในทุก Layer ที่ผ่านไป เปรียบเทียบกับกราฟล่าง คือ Neural Network ที่ Weight ถูก Initialize แบบ Normalized สังเกตว่า Gradient จากค่อนข้างนิ่ง ไม่ว่าจะผ่านไปกี่ Layer ก็ตาม
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

