จากใน ep ก่อน ที่เราได้เรียนรู้การทำ Normalization ข้อมูล Input ให้มี Mean=0, Std=1 เท่ากันในทุก Feature ว่ามีประโยชน์ในการเทรน Machine Learning อย่างไร คำถามก็คือ แล้วทำไมเราไม่ทำแบบเดียวกันใน Hidden Layer ของ Deep Neural Network ในขณะที่เราเทรนโมเดล Deep Learning ด้วยล่ะ
BatchNorm คืออะไร
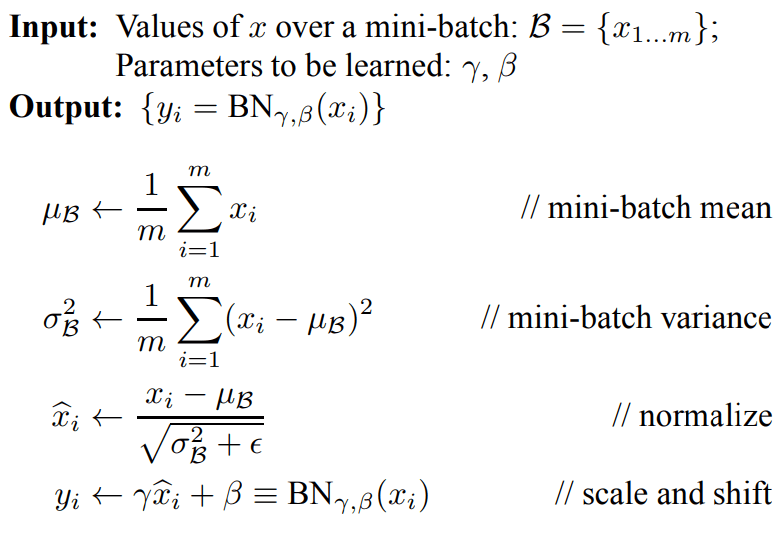
BatchNorm คือ เทคนิคที่ใช้ระหว่างการเทรน Machine Learning เพื่อปรับ Shift, Scale ให้ Activation ที่อยู่ภายใน Hidden Layer ของ Deep Neural Network ให้มีขนาดเหมาะสม ไม่เล็ก ไม่ใหญ่เกินไป โดยดูเทียบจาก Mean และ Standard Deviation ของทุก Activation ใน Layer ของทั้ง Batch นั้น คล้ายกับ Feature Scaling ของ Input และมีการเสริมด้วย Learning Parameter เพื่อให้โมเดลเรียนรู้ ที่จะปรับ Activation ให้เป็นที่ต้องการได้เอง
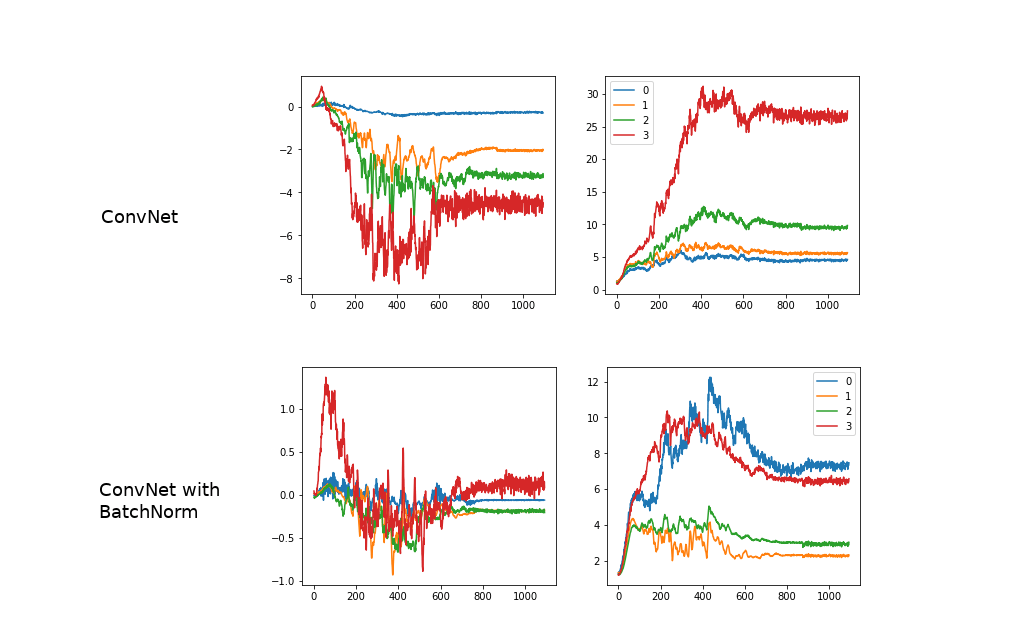
Batch Normalization ทำให้แต่ละ Layer ใน Neural Network สามารถเรียนรู้ได้ด้วยตัวเอง อย่างเป็นอิสระจากกันมากขึ้น ลดการผูกติดกับ Layer อื่น ๆ
BatchNorm มีประโยชน์หลายอย่าง ในการเทรน Machine Learning เช่น
- ช่วยให้ Gradient ไหลได้ดีขึ้น
- ทำให้เราสามารถใช้ Learning Rate ได้มากกว่าเดิม
- ลดความจำเป็นในการ Intialize ที่ซับซ้อน
- เป็นวิธีการ Regularization แบบหนึ่ง ในตัวเอง
- ถ้าใช้ BatchNorm ร่วมกับ Dropout สามารถใช้แทน L2 Regularization
BatchNorm ถือเป็นวิธี Regularization ที่นิยมอีกวิธีหนึ่ง ควบคู่กับ Dropout, Data Augmentation
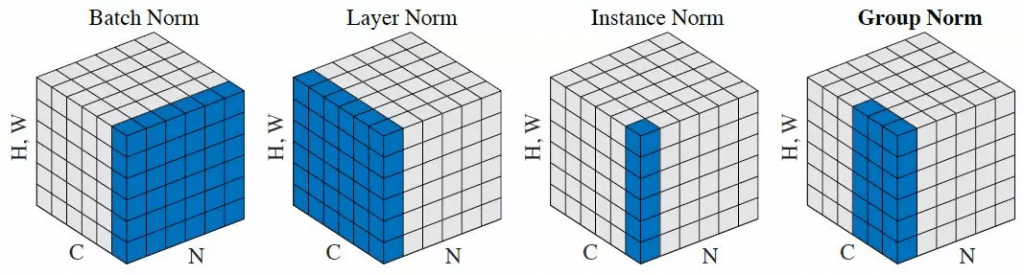
ยังมี Norm อีกหลายแบบ เช่น LayerNorm, InstanceNorm, GroupNorm แต่ประสิทธิภาพไม่ดีเท่า BatchNorm จะอธิบายต่อไป
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

