
ปัญหาหลักอย่างนึงในการเทรน Deep Learning คือ Dataset ของเรามีข้อมูลตัวอย่างไม่เพียงพอ สมมติว่าเราปิ๊งสุดยอดไอเดีย ที่จะสร้าง App ใหม่ ที่ใช้ Machine Learning ขึ้นมา เราเปิดเว็บเพื่อ Search Google หาข้อมูลตัวอย่าง มาไว้เทรนโมเดล เรานั่ง Search Google Images หารูปภาพอยู่หลายชั่วโมง นั่งจัด นั่ง Clean ข้อมูลที่ไม่เกี่ยวข้องออกไป สุดท้ายเราได้ รูปมา 500 รูป ถ้าหาแบบนี้ 10 วัน ก็ 5,000 รูป แต่เรารู้มาว่าโมเดลที่ดัง ๆ ใช้ข้อมูลในการเทรน เกิน 1 ล้านรูปขึ้นไปทั้งนั้น แล้วเราจะทำอย่างไรดี
Transfer Learning คืออะไร
Transfer Learning คือ การนำโมเดลของผู้อื่น ที่เทรนกับข้อมูลอื่นเรียบร้อยแล้ว ตัดเอาบางส่วนเฉพาะส่วนที่เราสนใจ มา Reuse ใช้ต่อ มาประกอบในการสร้างโมเดลใหม่ของเรา เช่น เรานำโมเดล Convolution Neural Network (CNN) ที่มี 100 Layer มาตัด Layer สุดท้ายทิ้งไป เปลี่ยนเป็น Layer ที่เหมาะกับงานของเราแทน แล้วเวลาเทรน ก็เทรนแค่ Layer ใหม่ที่อยู่ท้ายสุดอย่างเดียว เพื่อลดเวลา และข้อมูลที่ใช้ในการเทรน เพราะมี 99 Layer ที่ทำงานได้ถูกต้องอยู่แล้ว ไม่ต้องเทรนตั้งแต่ต้น เรื่อง Transfer Learning จะอธิบายเพิ่มเติมต่อไป
Data Augmentation คืออะไร
แต่ถึงเราจะใช้ Transfer Learning ประกอบโมเดลของเราขึ้นมาจากโมเดล Convolution Neural Network (CNN) ชื่อดัง เช่น ResNet, VGGNet, Inception รูปแค่ 500 รูปของเราก็ไม่พอเทรนอยู่ดี แล้วเราจะแก้อย่างไร
คำตอบ คือ เราก็เอารูป 500 รูปมา Recycle ให้เป็น 1,000 รูปสิ เช่น สมมติว่าเรามีรูปดอกไม้ 500 รูป เราเอารูปทั้งหมดมา Flip กลับซ้ายขวา ก็จะได้รูปเพิ่มขึ้นมาอีก 500 รูป รวมเป็น 1,000 รูป แบบง่าย ๆ เรียกว่า Data Augmentation

Data Augmentation ที่เป็นที่นิยมสำหรับรูปภาพมีอีกหลายอย่าง ได้แก่ ย่อ/ขยาย, หมุน ซ้าย/ขวา, Flip ซ้าย/ขวา/บน/ล่าง, Crop มุม, ปรับสีเข้ม/จืด, ปรับแสง สว่าง/มืด, ปรับ Contrast, ปรับ Perspective, เพิ่ม/ลด Noise, เบลอภาพ, Etc. ทั้งนี้ขึ้นอยู่กับงานด้วย เช่น ดอกไม้จะ Flip กลับหัวได้ไหม


Data Augmentation Zoom In 
Data Augmentation Zoom Out

Data Augmentation Rotate Right 15 Degree 
Data Augmentation Rotate Left 15 Degree

Data Augmentation Flip Horizontal 
Data Augmentation Flip Vertical

Data Augmentation Crop Bottom Right 
Data Augmentation Crop Top Left

Data Augmentation Decrease Saturation 
Data Augmentation Increase Saturation

Data Augmentation Brighten 
Data Augmentation Darken
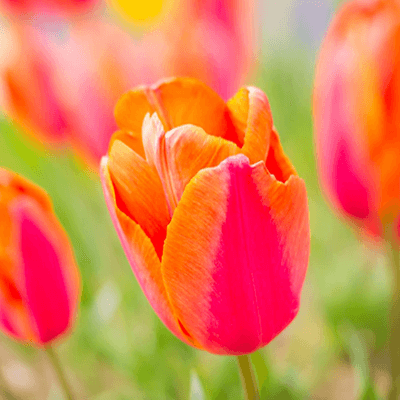
Data Augmentation Skew 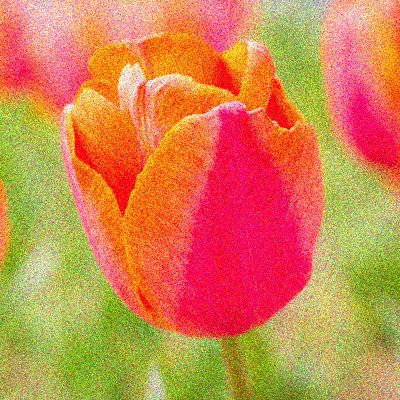
Data Augmentation Noise
ถ้าทำทั้งหมดผสม ๆ กันมากน้อย แบบ Random ไปเรื่อย ๆ จากรูปดอกไม้ ตอนแรกเพียง 500 รูป ก็จะกลายเป็นหมื่นเป็นแสนรูปได้ไม่จำกัด แต่คุณภาพของโมเดลก็จะขึ้นอยู่กับ ข้อมูลเริ่มต้น และ Hyperparameter ที่เรากำหนดว่าจะผสมอย่างไร
เรามาเริ่มกันเลยดีกว่า
Data Augmentation ใช้กันอย่างแพร่หลายในข้อมูลรูปภาพ แต่ก็ปัจจุบันมีการศึกษาเกี่ยวกับ Data Augmentation ในข้อมูลแบบอื่น ๆ เช่น ตาราง เสียงพูด และ ข้อความ NLP เช่น เปลี่ยนชื่อตัวละครจากชื่อนึงเป็นอีกชื่อนึง, เปลี่ยนสลับคำศัพท์ที่มีความหมายเหมือนกัน, Etc.
Regularization
Data Augmentation ถือว่าเป็นการ Regularization แบบหนึ่ง เพราะช่วยลด Overfit ช่วยให้โมเดลทำงานได้ Generalization ขึ้น ลดการจำข้อสอบ แต่ถือว่าเป็น Regularization ทางอ้อม เพราะไม่ได้ทำกับโมเดลโดยตรง แต่เป็นการทำกับข้อมูลแทน

