จาก ep ก่อน ๆ ที่เราได้พูดถึง Activation Function ยอดนิยมอย่าง ReLU ว่าเป็นฟังก์ชันที่ถูกใช้ในโมเดล Deep Learning มากที่สุดในปัจจุบัน แต่เมื่อเวลาผ่านไปมีโมเดลใหม่ ๆ Loss Function ใหม่ ๆ Optimizer ใหม่ ๆ ถูกสร้างขึ้นทุกปี แล้วจะมีฟังก์ชันใหม่อะไรมาแทน ReLU ได้หรือไม่ คำตอบอาจจะเป็น Mish Function
Mish Function คืออะไร
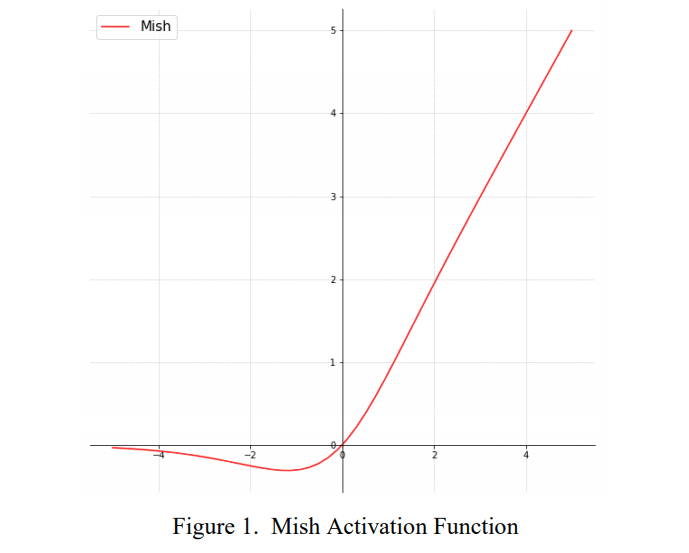
Mish มีช่วงระหว่างประมาณ ≈ -0.31 ถึง ∞
ด้วยแรงบันดาลใจจาก Swish Activation Function จาก Google ที่จะอธิบายต่อไป นักวิจัยได้พัฒนาปรับปรุงขึ้นมาเป็น Mish Function
Mish Function คือ Activation Function ออกแบบสำหรับ Neural Network มีความสามารถ Regularize ในตัวเอง และเป็นฟังก์ชันที่ไม่ใช่ฟังก์ชันทางเดียว (Non-Monotonic)
Mish Activation Function คือ SoftPlus Activation Function ที่ถูกปรับแต่ง (Gated) ตามสูตรคณิตศาสตร์ดังด้านล่าง
สมการของ SoftPlus Function
\( SoftPlus(x) = \ln(1 + e^x)\)สมการของ Mish Function
\(f(x) =x \tanh( SoftPlus(x)) = x \tanh( \ln(1 + e^x) )\)Derivative ของ Mish Function
\(f'(x) = \frac{e^x w}{\delta^2}\)เมื่อ
\(\delta = 2e^x + e^2x + 2 \\
w = 4 ( x + 1) + 4e^{2x} + e^{3x} + e^x(4x + 6)
\)
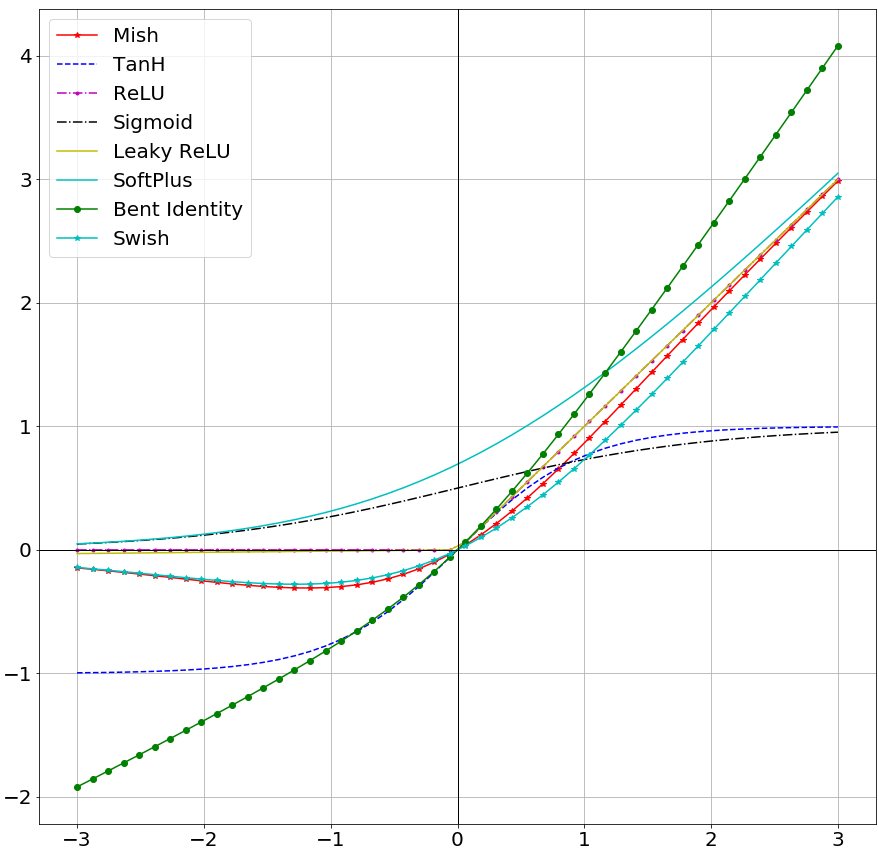
Mish Activation Function มีส่วนคล้ายกับ Swish ซึ่งแตกต่างกับ ReLU คือ มี Output ส่วนที่ค่อย ๆ ลดระดับลง ในช่วง Input ติดลบ (ไม่ใช่ 0 เหมือน ReLU) แต่ในส่วน Input เป็นบวกจะมี Output ใกล้เคียงเส้นตรง (เหมือน ReLU)
ทั้ง Mish Activation Function และ 1st derivative ของ Mish ไม่ใช่ฟังก์ชันทางเดียว (Non-Monotonic)
เรามาเริ่มกันเลยดีกว่า
ข้อดีของ Mish Function
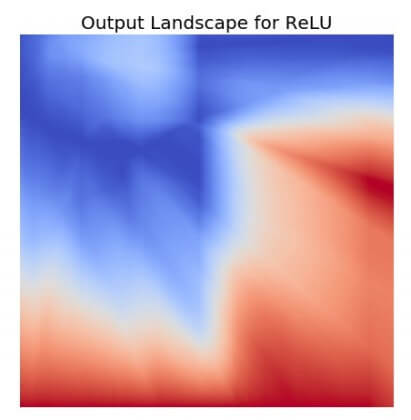

Output Landscape of Mish Activation Functions 

Output Landscape of Mish Activation Functions
- ได้ข้อดีของ ReLU มาทั้งหมด เนื่องจากในฝั่งบวก Output ใกล้เคียงเส้นตรง Slope คงที่ ขึ้นไปไม่สิ้นสุด
- อนุญาตให้ Input มาค่าเป็นลบได้ ทำให้ Gradient Flow ดีขึ้น
- ช่วงกว้างขึ้นกว่า ReLU จาก 0 ถึง ∞ เป็น ≈ -0.31 ถึง ∞
- เป็นฟังก์ชันที่มีความต่อเนื่อง Continuity ไม่หักมุม เหมือน ReLU ทำให้ Output Landscape มีความ Smooth โมเดลติด Local Minima น้อยลง
- สามารถใช้แทน ReLU ได้ทันทีไม่ต้องเปลี่ยนแปลงโมเดล แต่ใน Paper แนะนำให้ใช้ Learning Rate ที่ต่ำลงเพื่อผลลัพท์ที่ดีขึ้น
ข้อเสียของ Mish Function
- ใช้สูตรการคำนวนซับซ้อนกว่า ReLU และ Swish ทำให้ใช้เวลาทำงานมากกว่านิดหน่อย
- การเทรนใช้จำนวน Epoch มากกว่านิดหน่อย
ประสิทธิภาพ
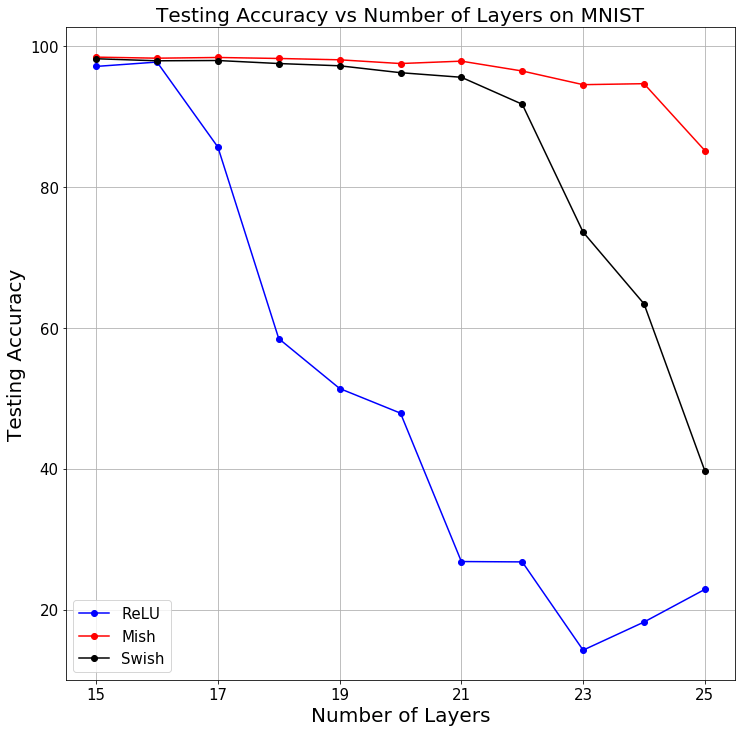
จากการทดสอบหลากหลายโมเดล หลาย Dataset ทั้งงาน Vision, NLP, Generative ปรากฎว่า Mish ชนะ Activation Function อื่น ๆ ในเกือบทุกการทดลอง ทั้ง Accuracy และ generalization ที่ดีกว่า โดยใช้เวลาเพิ่มขึ้นเพียงเล็กน้อย
และ 1 ในการทดสอบ (เคสที่ไม่มี Skip Connection) ถึงแม้เราจะเพิ่มจำนวน Layer ขึ้น ประสิทธิภาพของโมเดล Accuracy ก็ไม่ได้ลดลงรวดเร็วเท่ากับ ReLU เนื่องจากความ Smooth ของ Mish ทำให้ Gradient Flow ดีขึ้น
Credit
- https://arxiv.org/abs/1908.08681v2
- https://forums.fast.ai/t/meet-mish-new-activation-function-possible-successor-to-relu/53299
- https://github.com/digantamisra98/Mish
- https://github.com/lessw2020/mish
- https://medium.com/@lessw/meet-mish-new-state-of-the-art-ai-activation-function-the-successor-to-relu-846a6d93471f

