อย่างที่เราทราบกันดีว่า I/O หรือระบบ Input/Output เป็นอะไรที่ช้าที่สุด ของระบบคอมพิวเตอร์ การที่จะ Optimize ให้คอมพิวเตอร์ทำงานได้ประสิทธิภาพมากที่สุด ต้องใช้ความรู้ความเข้าใจ บริหารจัดการทรัพยากรส่วนต่าง ๆ เช่น CPU, GPU, Memory, Storage, Network ให้ทำงาน Utilize มากที่สุด ลด Bottleneck ที่ต้องรอข้อมูลระหว่างกัน แต่ในการเทรน Machine Learning ที่เราวิธีที่เราทำกันอยู่ Training Loop จะเริ่มต้นจาก อ่านข้อมูล, สับไพ่ข้อมูล, Split, Data Augmentation, Feed Forward, Loss Function, Backpropagation, Optimizer Update Weight แล้วเริ่มต้น Loop ใหม่ เป็นอย่างนี้ซ้ำ ๆ ไปเรื่อย ๆ ตามลำดับ โดยไม่ได้คำนึงถึงประเด็นด้านบน แล้วเราจะแก้ไขอย่างไร
Tag Archives: Train test split
MNIST คืออะไร
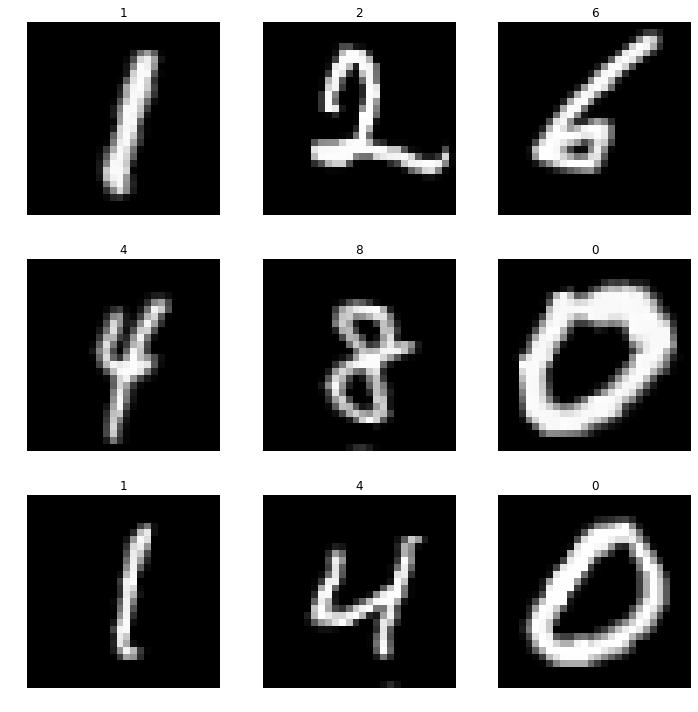
MNIST Database คือ ชุดข้อมูลรูปภาพของตัวเลขอารบิก 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ที่เขียนด้วยลายมือ 70,000 รูป MNIST คือ ชุดข้อมูลสำหรับไว้เทรน Artificial Intelligence (AI) เกี่ยวกับ Computer Vision / Image Processing
สับไพ่ข้อมูล DataLoader ด้วย Random Sampler และ Collate ป้อนโมเดล เทรน Machine Learning – Neural Network ep.7

ในแต่ละ Epoch ของการเทรน Machine Learning สอนโมเดล Deep Neural Network เราไม่ควรป้อนข้อมูลที่เรียงลำดับเหมือนกันทุกครั้งให้โมเดล ใน ep นี้เราจะมาสร้าง DataLoader เวอร์ชันใหม่ ที่จะสับไพ่ข้อมูลตัวอย่างก่อนป้อนให้โมเดล เป็นการลดการจำข้อสอบของโมเดล ช่วยให้โมเดล Generalization ได้ดีขึ้น ลด Variance ของโมเดล
ใช้ Dataset, DataLoader ป้อนข้อมูลให้ Neural Network ทีละ Batch สอน Refactor Training Loop – Neural Network ep.5

ใน ep นี้เราจะมาสร้าง Dataset และ DataLoader เพื่อเป็น Abstraction ในจัดการข้อมูลตัวอย่าง x, y จาก Training Set, Validation Set ที่เราจะป้อนให้กับ Neural Network ใช้เทรน ใน Training Loop ของ Machine Learning
Training Set คืออะไร ทำไมเราต้องแยกชุดข้อมูล Train / Test Split เป็น Training Set, Validation Set และ Test Set ใน Machine Learning
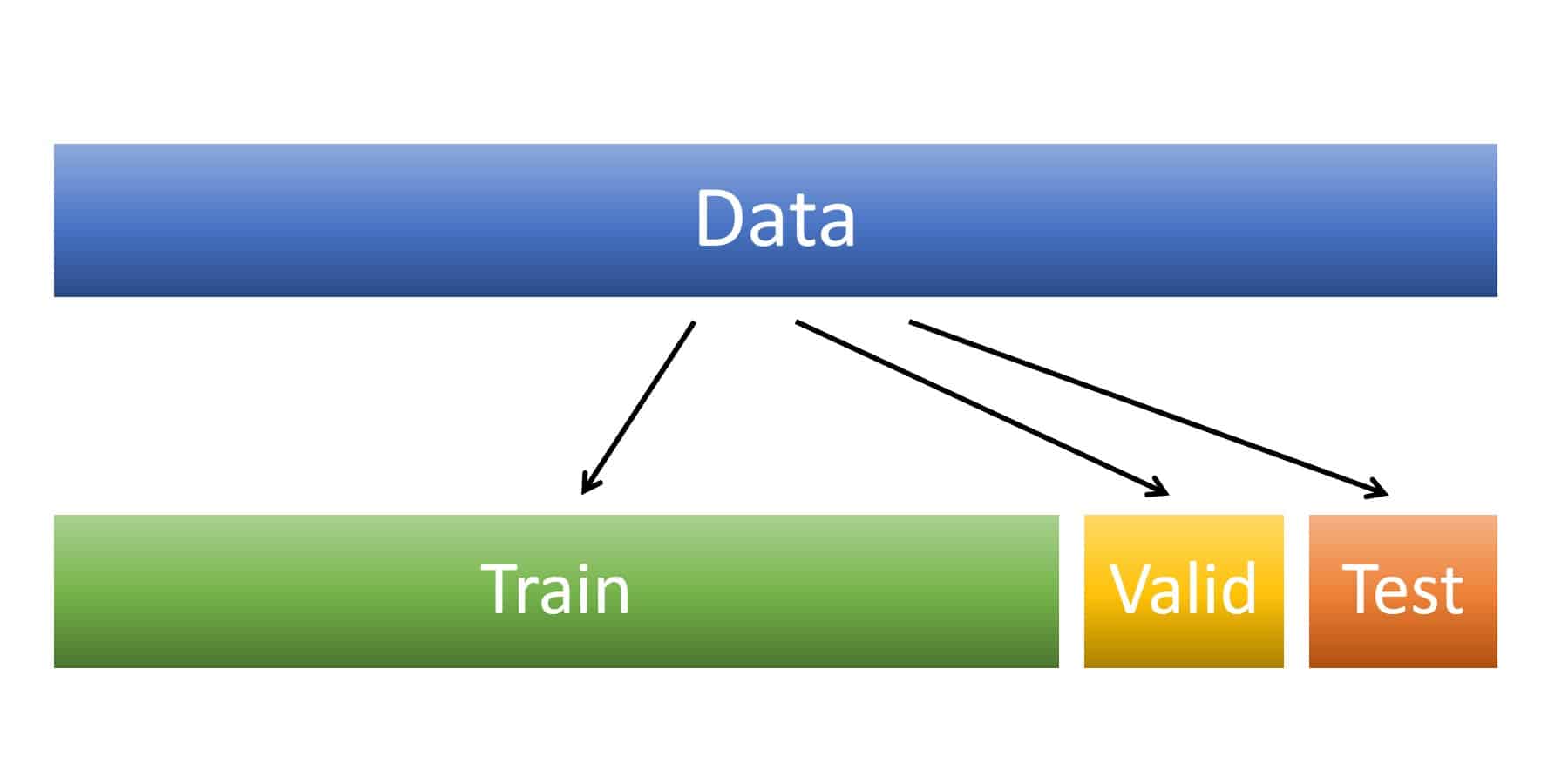
สมมติว่าถ้าเรามีข้อมูลอยู่ 10,000 Examples แล้วเราเอาทั้ง 10,000 ป้อนให้โมเดล Machine Learning ใช้สำหรับ Train ทั้งหมด แล้วเราจะเอาข้อมูลที่ไหนมาทดสอบการทำงานของโมเดล แล้วเราจะรู้ได้อย่างไรว่าโมเดลทำงานได้แมนยำแค่ไหน กับข้อมูลที่มันไม่เคยเห็นมาก่อน แล้วเราควรแก้ปัญหานี้อย่างไร