อย่างที่เราทราบกันดีว่า I/O หรือระบบ Input/Output เป็นอะไรที่ช้าที่สุด ของระบบคอมพิวเตอร์ การที่จะ Optimize ให้คอมพิวเตอร์ทำงานได้ประสิทธิภาพมากที่สุด ต้องใช้ความรู้ความเข้าใจ บริหารจัดการทรัพยากรส่วนต่าง ๆ เช่น CPU, GPU, Memory, Storage, Network ให้ทำงาน Utilize มากที่สุด ลด Bottleneck ที่ต้องรอข้อมูลระหว่างกัน
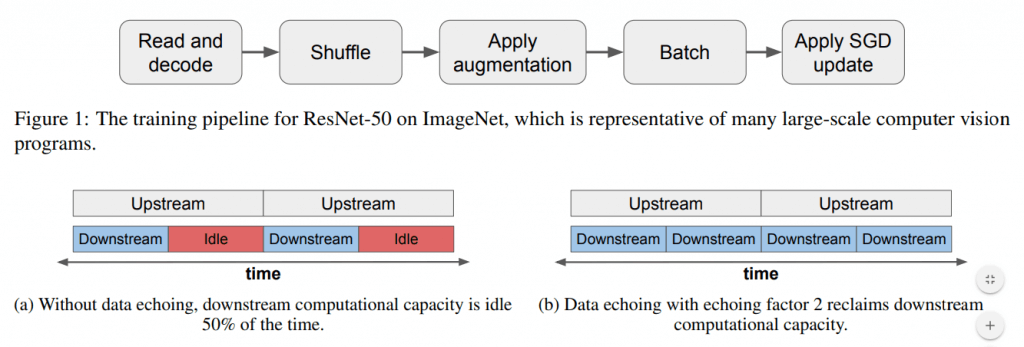
แต่ในการเทรน Machine Learning ที่เราวิธีที่เราทำกันอยู่ Training Loop จะเริ่มต้นจาก อ่านข้อมูล, สับไพ่ข้อมูล, Split, Data Augmentation, Feed Forward, Loss Function, Backpropagation, Optimizer Update Weight แล้วเริ่มต้น Loop ใหม่ เป็นอย่างนี้ซ้ำ ๆ ไปเรื่อย ๆ ตามลำดับ โดยไม่ได้คำนึงถึงประเด็นด้านบน แล้วเราจะแก้ไขอย่างไร
Data Echoing คืออะไร
มี Paper ฉบับหนึ่ง ชื่อ Faster Neural Network Training with Data Echoing โดย Dami Choi, Alexandre Passos, Christopher J. Shallue, George E. Dahl เสนอแนวคิดง่าย ๆ ที่จะมาช่วยแก้ไขปัญหานี้ คือ Data Echoing
แนวคิดของ Data Echoing คือเอา Data เดิมที่อยู่ในระบบอยู่แล้ว มาป้อนให้กับโมเดลใหม่ ระหว่างที่รอ Data ใหม่ ถึงแม้ว่าจะเป็น Data ที่โมเดลเพิ่งจะเห็นไป คุณภาพอาจจะไม่ดีเหมือน Data ใหม่ แต่ก็ดีกว่าปล่อยให้ โมเดล / GPU อยู่ว่าง ๆ และอย่างไรก็ตาม Epoch หน้าโมเดลก็ต้องเจอข้อมูลเหล่านี้ใหม่อยู่ดี

ส่วนปัญหาที่ว่า Data เก่า ก็ให้ใช้ Data Augmentation เข้ามาช่วย ให้เหมือนกับว่าเป็น Data ใหม่อีก 1 Batch ซึ่งแนวคิดใน Paper มีอีกหลายวิธี ทั้ง Echoing ก่อน/หลัง Data Augmentation, Echoing ทีละ Batch หรือทีละ Example, วิธีการ Shuffle สับไพ่ข้อมูล, จำนวนที่ Echoing โดยเราสามารถประยุกต์ใช้ Data Echoing ได้ในงานที่หลากหลาย ไม่ว่าจะเป็น Image Classification, Object Detection และ Language Modeling จะอธิบายต่อไป
ใน ep นี้ เราจะทดลองเปรียบเทียบกันแบบง่าย ๆ ระหว่าง Batch Size ขนาดต่าง ๆ เป็น Baseline และ ลดขนาด Batch Size ลงมา แต่เราจะเพิ่ม Data Echoing เข้าไปเสริมก่อน Data Augmentation แล้วดูว่าโมเดลของเราจะ Converge เร็วขึ้นจริงหรือไม่

