
จาก ep ที่แล้ว AI จำแนกรูปภาพ หมา แมว 37 สายพันธุ์ เราได้ใช้ fastai version 1 ในการทำ Image Classification ได้ผลลัพธ์แม่นยำ 94% โดยใช้เวลาเทรนเพียงแค่ไม่เกิน 5 นาที กับ Code หลัก ๆ เพียงแค่ 3 บรรทัด เวลาผ่านไปหลายเดือน ขณะนี้ fastai ออกเวอร์ชันใหม่ เป็น fastai2 มี API ที่เปลี่ยนไปเล็กน้อย เน้นความยืดหยุ่นมากขึ้น ช่วยให้เราเทรนโมเดล และข้อมูลที่มีความซับซ้อนได้อย่างสะดวกยิ่งขึ้น
Dataset

ในเคสนี้ เราจะใช้ข้อมูลจาก Oxford-IIIT Pet Dataset by O. M. Parkhi et al., 2012 เหมือนเดิม ซึ่งเป็นชุดข้อมูลรูปภาพหมา 25 พันธุ์ และรูปแมว 12 พันธุ์ รวมเป็น 37 หมวดหมู่
Model Architecture
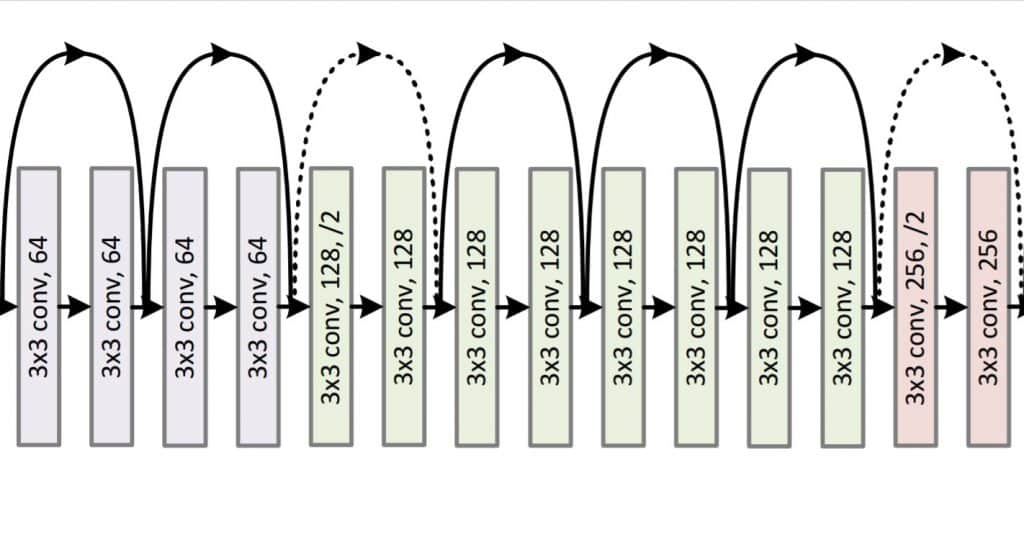
เราจะใช้ resnet34 และ resnet50 ซึ่งเป็นโมเดลแบบ Convolutional Neural Network (CNN, ConvNet) ที่ถูกเทรนกับ ImageNet Dataset มาเรียบร้อยแล้ว โมเดลในตระกูล ResNet เป็นโมเดลที่ได้รับความนิยม และมีประสิทธิภาพสูง

