งานทาง NLP อีกงาน ที่เป็นเรื่องพื้นฐานสุด ๆ ที่เราต้องเรียนรู้ ก่อนที่จะเข้าใจ ภาษาใด ๆ คือ Part of Speech ส่วนของคำพูด หรือ คำไหนทำหน้าที่อะไรในประโยค เช่น คำนาม กริยา กรรม
เมื่อได้คำนามมาแล้ว เราจะมาเรียนรู้ Named-Entity Recognition ทำ Named-Entity Tagging ว่าคำ ๆ นี้ เป็น ชื่อสิ่งที่อยู่ในโลกความเป็นจริงหรือไม่ ประเภทอะไร เช่น ชื่อคน สถานที่ องค์กร
Part of Speech คืออะไร
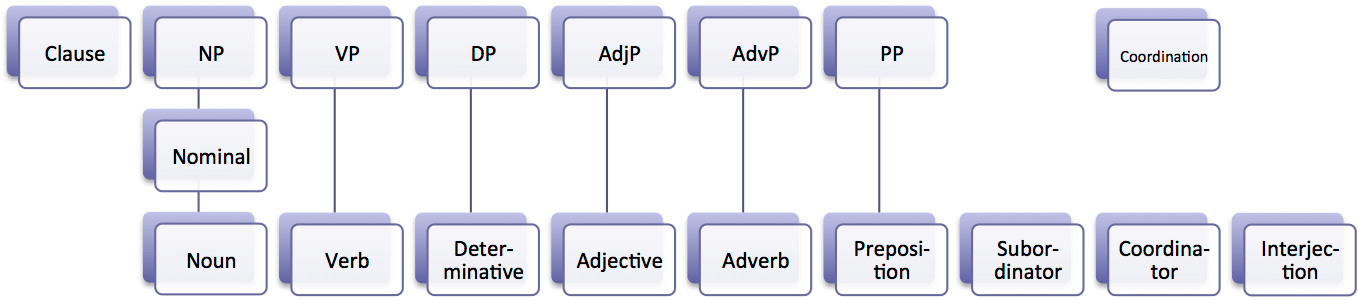
Part of Speech ส่วนของคำพูด หรือ ประเภทของคำหรือชนิดของคำที่อยู่ในประโยค เช่น คำนาม คำสรรพนาม คำกริยา คำวิเศษณ์ คำบุพบท คำสันธาน noun, pronoun, verb, adjective, adverb, preposition, conjunction และ interjection
เนื่องจาก ประโยค วลี คำพูด ต่าง ๆ ที่เราใช้สื่อสารกันนั้น ล้วนเกิดขึ้นจากการนำคำต่าง ๆ มาประกอบกันเป็นส่วนต่าง ๆ ที่ทำหน้าที่ต่างกันในประโยค
Part of Speech Tagging คืออะไร
Part of Speech Tagging คือ การแปะป้ายว่า คำไหน เป็นส่วนไหนของประโยค เช่น Somchai loves you ( Somchai เป็น คำนาม Noun, loves เป็น คำกริยา Verb, you เป็นคำสรรพนาม Pronoun)
Named-Entity Recognition / Named-Entity Tagging คืออะไร
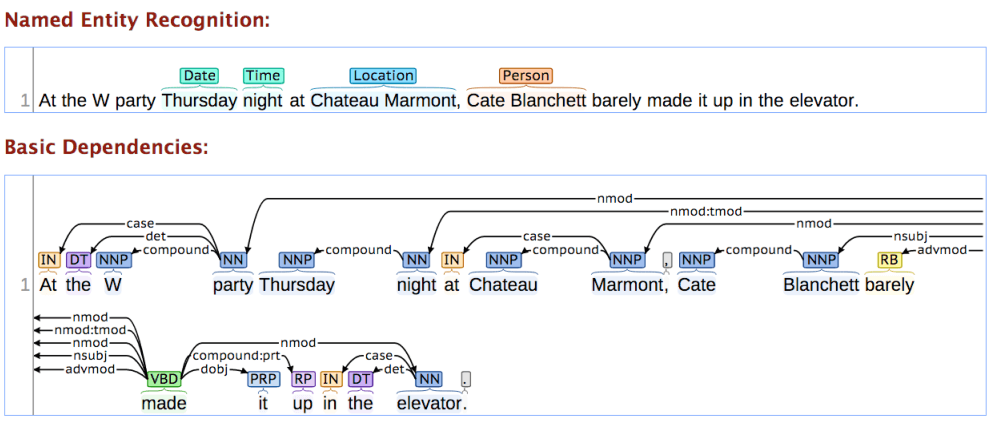
Named-Entity Recognition หรือ Named Entity Tagging คือ กระบวนการในการหาตำแหน่ง และ แปะป้ายชื่อเฉพาะของสิ่งต่าง ๆ ที่อยู่ในเอกสาร เช่น ชื่อคน ชื่อองค์กร สถานที่ ตัวเลข จำนวนเงิน วันเวลา persons, locations, organizations, products, medical codes, time expressions, quantities, monetary values, percentages

