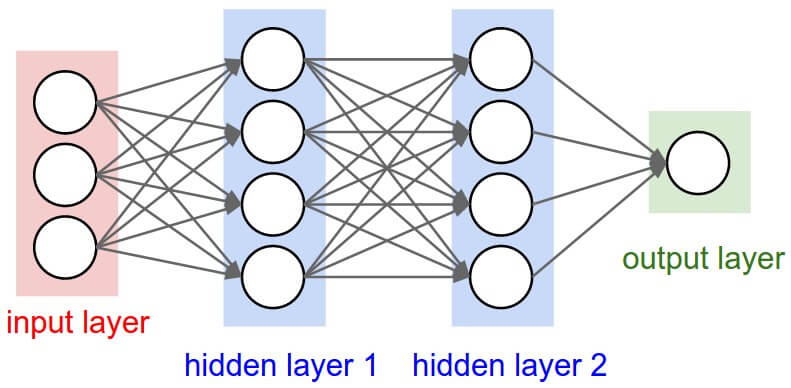
ใน ep นี้ เราจะมาสร้าง Neural Network สำหรับงาน Classification ด้วยการประกอบชิ้นส่วนทุกอย่างใน ep ก่อน ๆ เข้าด้วยกัน ขึ้นมาเป็น 2 Layers Deep Neural Network ใช้ ReLU Activation Function พร้อม Initialize Weight และ Bias
แล้วสร้าง Training Loop เพื่อเริ่มต้นเทรน, ป้อนข้อมูลตัวอย่าง Batch แรกให้ Feed Forward, นำ Output yhat ไปเทียบกับ y หาค่า Cross Entropy Loss, Backpropagation, หา Gradient, อัพเดท Weight และ Bias ด้วย SGD, ก่อนเริ่มต้นเทรน Batch / Epoch ถัดไป
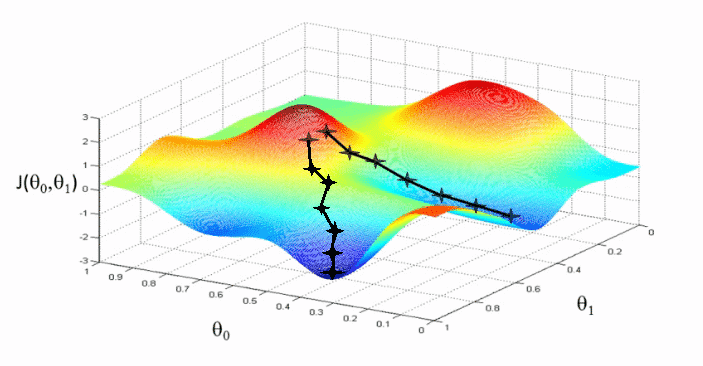
หลังจากนั้น เราจะมาเช็คกันดูว่า โมเดลของเราทำงานถูกต้อง แม่นยำ แค่ไหน ได้ Accuracy เท่าไร เมื่อเราเทสกับ Validation Set
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

