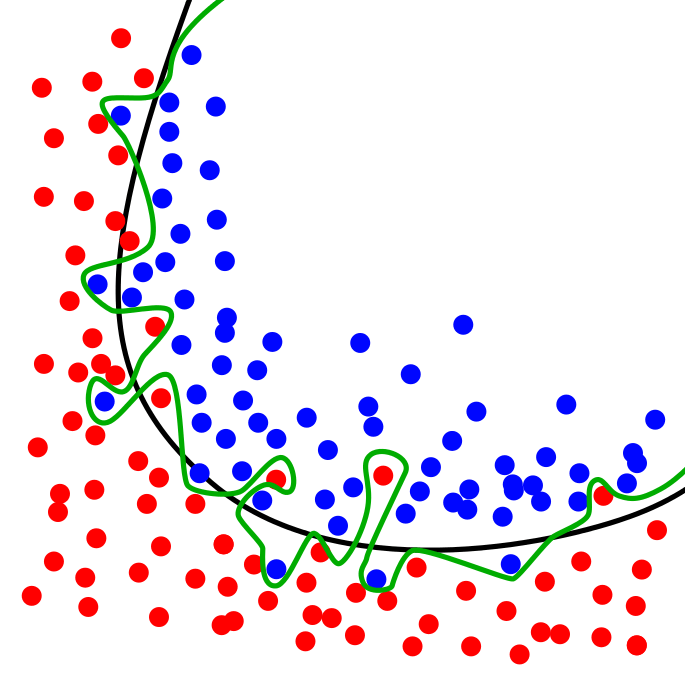
ในการเทรน Machine Learning การทดสอบว่าโมเดล Neural Network ทำงานเป็นอย่างไร ที่ถูกต้องเราไม่ควรเทสกับข้อมูล ใน Training Set ที่เราป้อนให้โมเดลในขณะเทรน เพราะจะทำให้ไม่ได้ค่าที่แท้จริง ถ้าโมเดลใช้วิธีจำข้อสอบ เรียกว่า Overfit เมื่อเทสแล้วจะได้คะแนนสูงผิดปกติ
ที่ถูกคือ เราควรเทสกับข้อมูลที่โมเดลไม่เคยเห็นมาก่อน ใน Validation Set ที่เรากันเอาไว้ก่อนหน้าที่จะเริ่มต้นเทรน
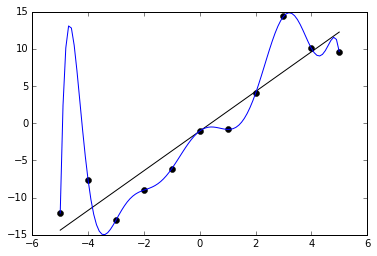
เมื่อเราใช้ข้อมูลที่โมเดลไม่เคยเห็น ใน Validation Set มาเทสโมเดล แล้วได้ผลดี ทำให้เราสามารถคาดหวังได้ว่า โมเดลจะทำงานกับข้อมูลจากโลกภายนอก ที่ไม่เคยเห็นมาก่อนได้ดี เช่นกัน Train/Validation/Test Split คืออะไร คลิก
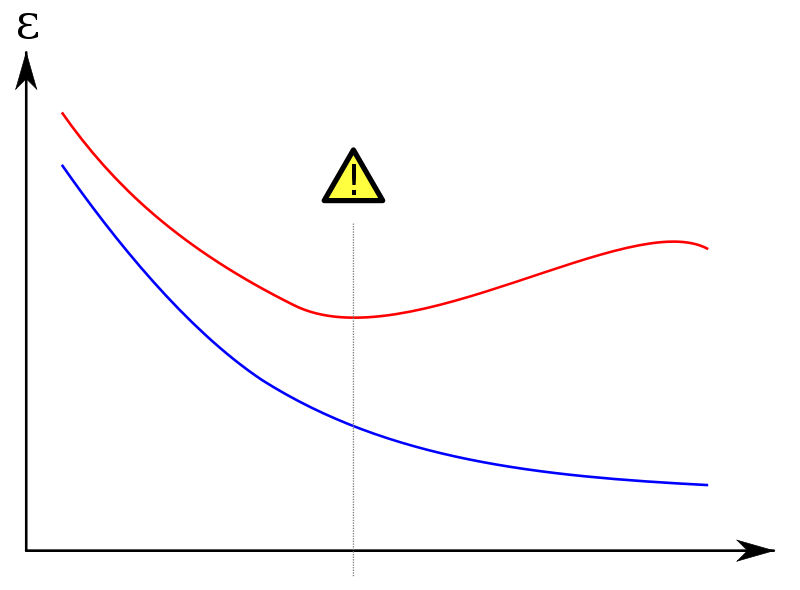
เมื่อเกิด Overfit โมเดลจะจำข้อสอบ ทำให้เมื่อเทรนไปเรื่อย ๆ Loss และ Accuracy ของ Training Set จะดีขึ้นเรื่อย ๆ (เส้นสีน้ำเงิน) ต่างกับเมื่อเราไปเทสกับ Validation Set ผล Loss และ Accuracy จะยิ่งแย่ลงเรื่อย ๆ (เส้นสีแดง)
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

