สมมติว่าถ้าเรามีข้อมูลอยู่ 10,000 Examples แล้วเราเอาทั้ง 10,000 ป้อนให้โมเดล Machine Learning ใช้สำหรับ Train ทั้งหมด แล้วเราจะเอาข้อมูลที่ไหนมาทดสอบการทำงานของโมเดล แล้วเราจะรู้ได้อย่างไรว่าโมเดลทำงานได้แมนยำแค่ไหน กับข้อมูลที่มันไม่เคยเห็นมาก่อน แล้วเราควรแก้ปัญหานี้อย่างไร
การที่โมเดลสามารถทำงานได้แม่นยำกับข้อมูลที่ไม่เคยเห็นมาก่อน เรียกว่า Generalization เป็นคอนเซ็ปท์สำคัญ ของการพัฒนาระบบ Machine Learning เพราะถ้าเรามีระบบที่ทำงานได้แม่นยำเฉพาะกับข้อมูลที่มันเคยเห็นมาก่อน ก็เหมือนกับเป็นนักเรียนที่จำข้อสอบ เข้าไปสอบ ทำถูกเฉพาะโจทย์ที่เหมือนเป๊ะเท่านั้น ไม่สามารถพลิกแพลงกับโจทย์ที่แตกต่างกันได้แม้แต่เล็กน้อยก็ตาม เมื่อเอามาใช้งานจริง เจอข้อมูลจริง ๆ โมเดลก็จะมีประสิทธิภาพความแม่นยำต่ำจนรับไม่ได้ เรียกว่า Overfit
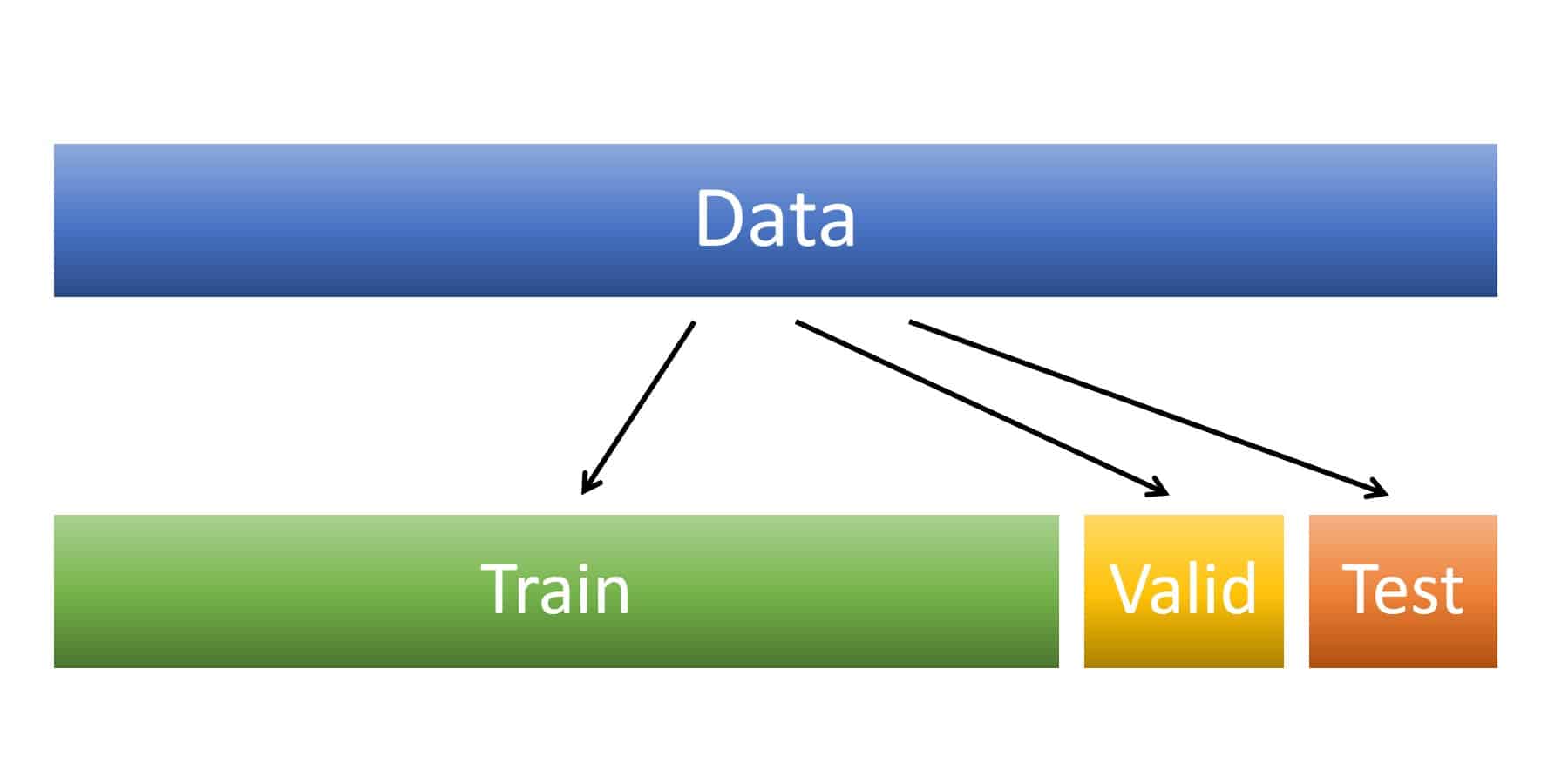
Training/Test Set Split
เราจึงควรแบ่งข้อมูล Split ออกเป็น 2 ส่วน คือ Training Set และ Test Set เช่น 9,000 เป็น Training Set และ 1,000 เป็น Test Set
- Training Set ใช้สำหรับป้อนให้โมเดลใช้เทรน
- Test Set ใช้สำหรับทดสอบหา Metrics หลังจากเทรนเสร็จว่า โมเดลจะทำงานได้ดีแค่ไหนกับข้อมูลที่ไม่เคยเห็นมาก่อน
เมื่อเราใช้การแบ่งข้อมูลเป็น 2 ส่วนนี้ ในการ Train, Test, จูน Hyperparameter, Train, Test, จูน Hyperparameter, Train, Test, จูน Hyperparameter, … เพื่อเลือกโมเดลที่ทำงานได้แม่นยำที่สุดกับ Test Set เพื่อที่เราหวังว่าจะได้โมเดลที่ทำงานได้ดีกับข้อมูลที่ไม่เคยเห็นมาก่อน เราก็จะเจอปัญหาใหม่
ปัญหานั้นก็คือ Bias การใช้ Test Set หลาย ๆ ครั้งแบบนี้ ทำให้โมเดลที่เราเลือกว่าทำงานได้ดีที่สุดนั้น Bias ไปทาง Test Set เหมือนกับบางส่วนของโมเดลนั้นจำ Test Set เข้าไปด้วย ทำเกิดปัญหา Generalization เหมือนเดิม คือเราไม่สามารถมั่นใจได้ว่า โมเดลของเราจะทำงานได้ดีกับข้อมูลที่มันไม่เคยเห็นมาก่อน
Training/Validation/Test Set Split
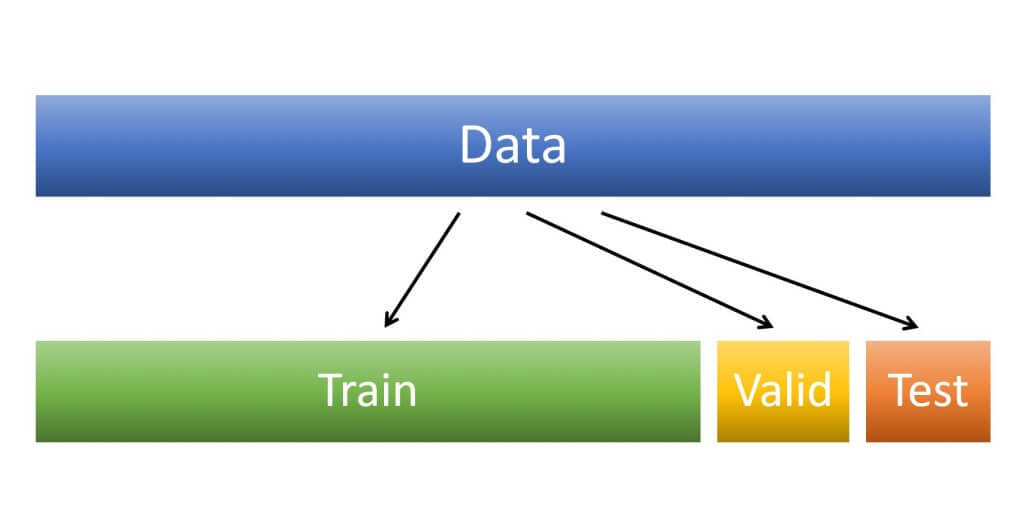
ดังนั้นเราจึงควรแบ่งข้อมูล Split ออกเป็น 3 ส่วน คือ Training Set, Validation Set และ Test Set เช่น 8,000 เป็น Training Set แบ่งอีก 1,000 เป็น Validation Set และ 1,000 เป็น Test Set
- Training Set ใช้สำหรับป้อนให้ใช้เทรน
- Validation Set ใช้สำหรับทดสอบหา Metrics หลังจากเทรนเสร็จว่าโมเดลทำงานได้ดีแค่ไหน และหลังจากจูนแต่ละครั้งโมเดลไหนทำงานได้ดีกว่ากัน
- Test Set ใช้สำหรับทดสอบหลังจากได้โมเดลที่ดีที่สุดมาแล้ว ว่าโมเดลจะทำงานได้ดีแค่ไหนกับข้อมูลที่ไม่เคยเห็นมาก่อน
เมื่อเราใช้การแบ่งข้อมูลเป็น 3 ส่วนนี้ ในการ Train, Validate, จูน Hyperparameter, Train, Validate, จูน Hyperparameter, Train, Validate, จูน Hyperparameter, … เพื่อเลือกโมเดลที่ทำงานได้แม่นยำที่สุดกับ Validation Set สุดท้ายแล้วเราถึงจะทดสอบกับ Test Set ที่เป็นตัวแทนของข้อมูล Real-World ว่าจะทำงานได้ดีแค่ไหน เมื่อเราปล่อยระบบออกไปใช้จริง
หมายเหตุ
- ข้อมูลที่ได้มาควรให้คล้ายกับข้อมูล ที่ระบบจะเจอเมื่อใช้งานจริง Real-World มากที่สุด จะได้ไม่มีปัญหาว่าเทรนข้อมูลแบบนึง เวลาใช้จริงเจอข้อมูลอีกแบบ (Training/Serving Skew) เช่น ข้อมูลเป็นฝรั่ง แต่ใช้งานจริงกับคนเอเชีย เป็นต้น
- ก่อนการ Split ข้อมูลควร Shuffle หรือสับไพ่ ให้ข้อมูลทุกชุดมีการกระจายของข้อมูล หรือ Distribution ใกล้เคียงกัน ไม่เอนเอียง (Data Skew)
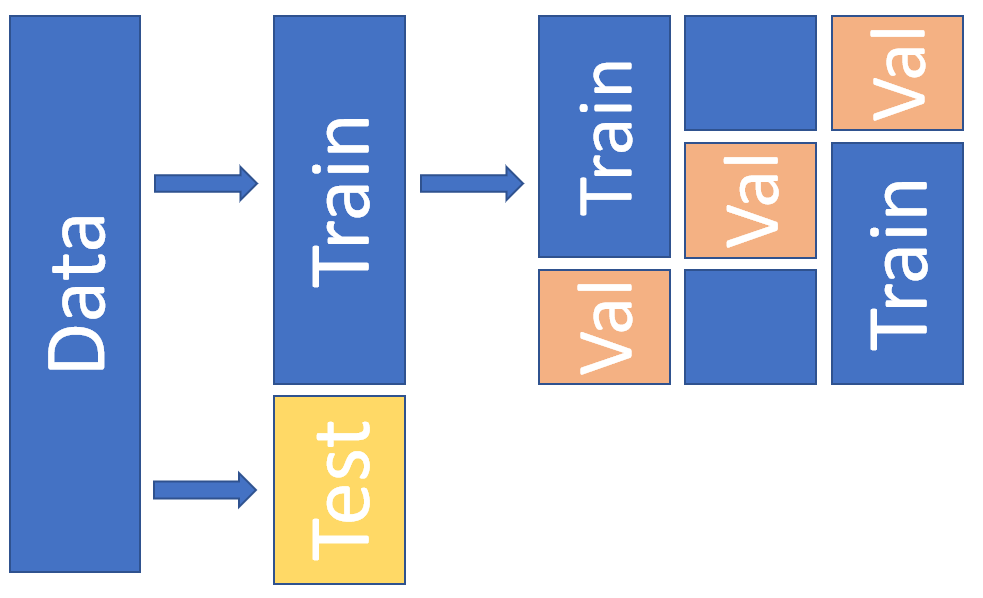
- จริง ๆ แล้ว การแบ่งข้อมูล Split มีหลายแบบ มีแบบเป็นที่นิยมสำหรับกรณีที่เรามีข้อมูลไม่มาก เรียกว่า Cross Validation ซึ่งไว้เราจะอธิบายต่อไป
- ในการจัดประกวดแข่งขัน เช่น Kaggle นั้น จะให้มาแค่ 2 อย่าง 1. Training Set คือ ข้อมูลตัวอย่างสำหรับเทรน มี Label ครบถ้วน 2. Test Set คือข้อมูลที่ไม่มี Label ให้มาด้วย ให้เราเป็นผู้เติม Label เอง แล้วส่งให้ Kaggle เพื่อตรวจให้คะแนน ว่าโมเดลของเราทำนายได้ถูกต้องแค่ไหน ส่วน Validation Set นั้นให้เราแบ่งจาก Training Set เอาเอง

