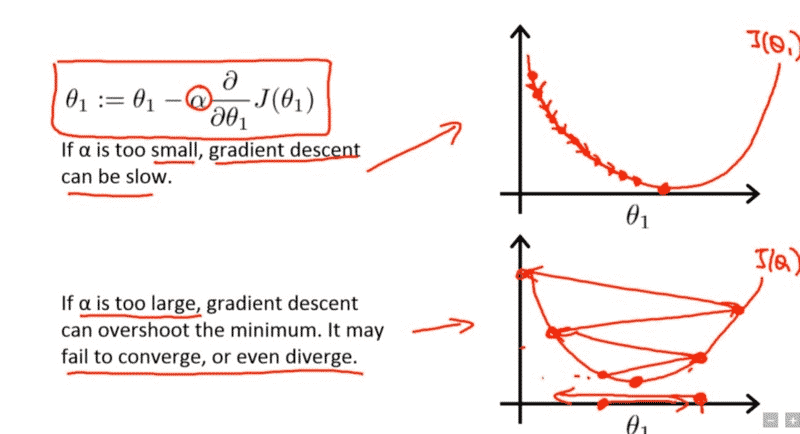
จาก ep ก่อน เราได้รู้จัก Hyperparameter ที่สำคัญที่สุดในการเทรน Machine Learning ชื่อ Learning Rate แต่ปัญหาคือ ถ้าเรากำหนดค่า Learning น้อยไปก็ทำให้เทรนได้ช้า แต่ถ้ามากเกินไปก็ทำให้ไม่ Converge หรืออาจจะ Error ไปเลย แล้วเราจะมีวิธีใด ที่จะหาค่า Learning Rate ที่ดีที่สุด มาใช้เทรน Deep Neural Network ของเรา
Tag Archives: artificial neural network
ทดสอบ Metrics ของ Neural Network ด้วยข้อมูลจาก Validation Set ระหว่างการเทรน Machine Learning – Neural Network ep.8
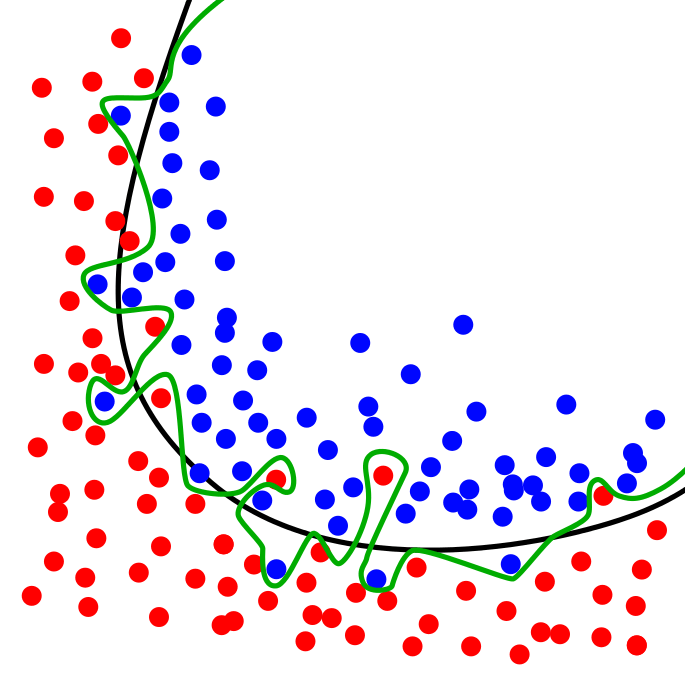
ในการเทรน Machine Learning การทดสอบว่าโมเดล Neural Network ทำงานเป็นอย่างไร ที่ถูกต้องเราไม่ควรเทสกับข้อมูล ใน Training Set ที่เราป้อนให้โมเดลในขณะเทรน เพราะจะทำให้ไม่ได้ค่าที่แท้จริง ถ้าโมเดลใช้วิธีจำข้อสอบ เรียกว่า Overfit เมื่อเทสแล้วจะได้คะแนนสูงผิดปกติ ที่ถูกคือ เราควรเทสกับข้อมูลที่โมเดลไม่เคยเห็นมาก่อน ใน Validation Set ที่เรากันเอาไว้ก่อนหน้าที่จะเริ่มต้นเทรน
Refactor สร้าง Optimizer สำหรับอัพเดท Parameter ของ Neural Network ในการเทรน Deep Learning – Neural Network ep.6
ใน ep นี้เราจะมา Refactor Model สร้าง Module, Parameter และ Optimizer เป็น Abstraction ในจัดการการอัพเดท Parameter ของโมเดล ด้วยอัลกอริทึมต่าง ๆ เพื่อลดความซับซ้อน ของ Training Loop ทำให้การเทรน Neural Network ยืดหยุ่นขึ้น เราจะใช้โค้ดจาก Neural Network ep 5 เป็นโค้ดเริ่มต้น นำมา Refactor ต่อ
สร้าง Training Loop แบบง่าย เริ่มต้นเทรน Neural Network ด้วย Mini-Batch SGD – Neural Network ep.4
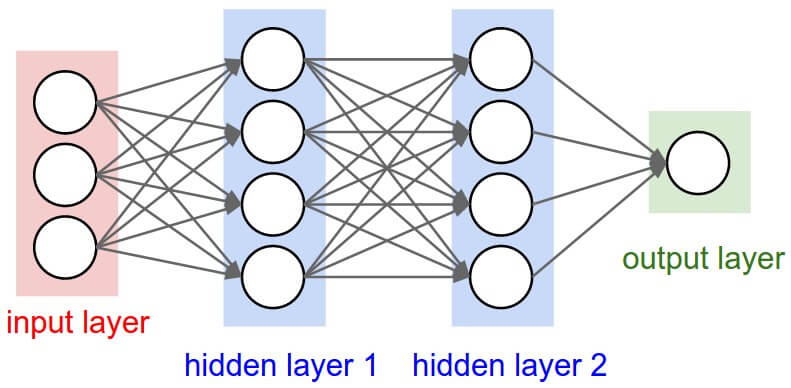
ใน ep นี้ เราจะมาสร้าง Neural Network สำหรับงาน Classification ด้วยการประกอบชิ้นส่วนทุกอย่างใน ep ก่อน ๆ เข้าด้วยกัน ขึ้นมาเป็น 2 Layers Deep Neural Network ใช้ ReLU Activation Function พร้อม Initialize Weight และ Bias
Cross Entropy Loss คืออะไร Logistic Regression คืออะไร Log Loss คืออะไร – Loss Function ep.3

ใน ep ก่อนเราพูดถึง Loss Function สำหรับงาน Regression กันไปแล้ว ในตอนนี้เราจะมาพูดถึง Loss Function อีกแบบหนึ่ง ที่สำคัญไม่แพ้กัน ก็คือ Loss Function สำหรับงาน Classification เรียกว่า Cross Entropy Loss หรือ Logistic Regression
One Hot Encoding คืออะไร ประโยชน์ ข้อดี ข้อเสีย ของ One Hot Encoding ทำไมต้องใช้ One Hot Encoding ใน Machine Learning

ในการศึกษา Machine Learning เราจะพบคำว่า One Hot Encoding อยู่เสมอ ๆ ใน ep นี้เราจะมาเรียนรู้กันว่า One Hot Encoding คืออะไร One Hot Encoding มีประโยชน์อย่างไร ช่วยแก้ปัญหาอะไร ทำไม Machine Learning ต้องใช้ One Hot Encoding
Softmax Function คืออะไร เราจะใช้งาน Softmax Function อย่างไร ประโยชน์ของ Softmax
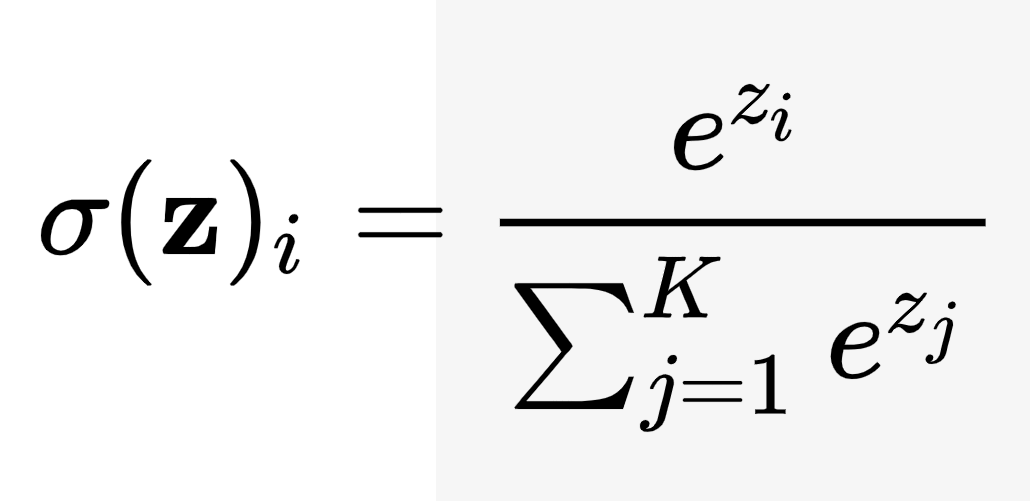
Softmax Function หรือ SoftArgMax Function หรือ Normalized Exponential Function คือ ฟังก์ชันที่รับ Input เป็น Vector ของ Logit จำนวนจริง แล้ว Normalize ออกมาเป็นความน่าจะเป็น Probability ที่ผลรวมเท่ากับ 1 หรือเข้าใจง่าย ๆ ว่า Softmax รับตัวเลขเข้าไป แล้วแปลงออกมาเป็น Probability เรามาดูตัวอย่างกันจะเข้าใจง่ายขึ้น
Neural Network คืออะไร Artificial Neural Network ทำงานอย่างไร สอนสร้าง Deep Neural Network แบบเข้าใจง่าย – Neural Network ep.1
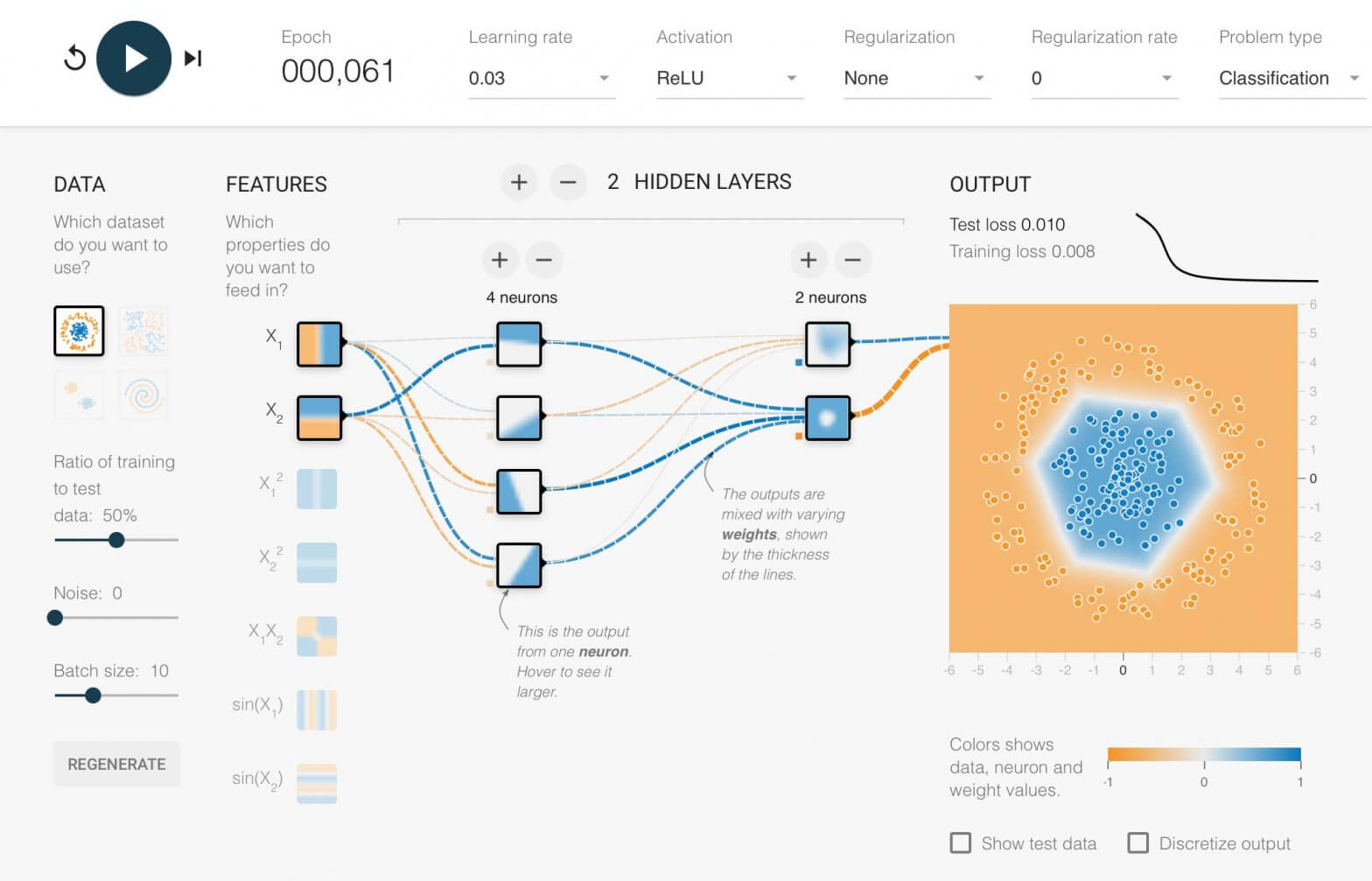
Neural Network หรือ Artificial Neural Network คือ โครงข่ายประสาทเทียม เป็นสาขาหนึ่งของปัญญาประดิษฐ์ Artificial Intelligence (AI) เป็นแนวคิดที่ออกแบบระบบโครงข่ายคอมพิวเตอร์ ให้เลียนแบบการทำงานของสมองมนุษย์ ใน ep นี้เราจะมาดูกันว่า ภายใน Neural Network นั้นทำงานอย่างไร และเราจะมาสร้าง 2 Layers Deep Neural Network กันตั้งแต่ Tensor, Matrix และฟังก์ชันคณิตศาสตร์พื้นฐาน บวก ลบ คูณ หาร แบบเข้าใจง่าย ๆ ไปทีละขั้นด้วยกัน
ตัวอย่าง Linear Regression ด้วย Stochastic Gradient Descent (SGD) พื้นฐานของ Neural Network – Optimization ep.2
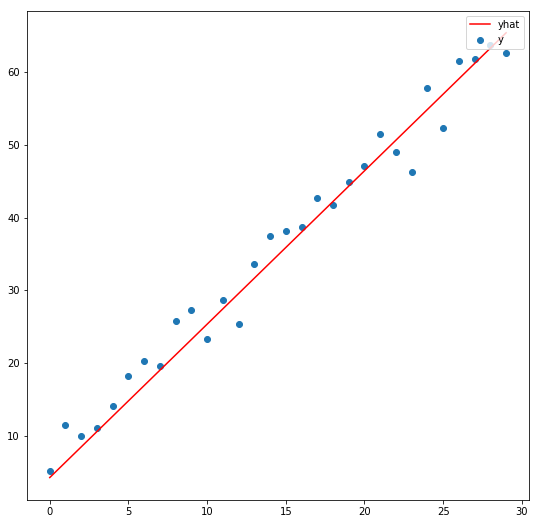
จาก ep ที่แล้วที่เราเล่าถึงคอนเซ็ปต์ของ SGD ไป ใน ep นี้เราจะมาดูตัวอย่างโค้ดแบบง่ายที่สุด ซับซ้อนน้อยที่สุด ซึ่งเป็นพื้นฐานสำคัญของ Machine Learning แบบ Neural Network คือ Linear Regression ด้วยอัลกอริทึม Stochastic Gradient Descent (SGD) แต่ในการหา Slope นั้นเราไม่ต้อง Diff เอง แต่เราจะใช้ความสามารถ ของ Pytorch เรียกว่า Autograd หา Gredient ของ Parameter ทุกตัวให้โดยอัตโนมัติ
ReLU Function คืออะไร ทำไมถึงนิยมใช้ใน Deep Neural Network ต่างกับ Sigmoid อย่างไร – Activation Function ep.3
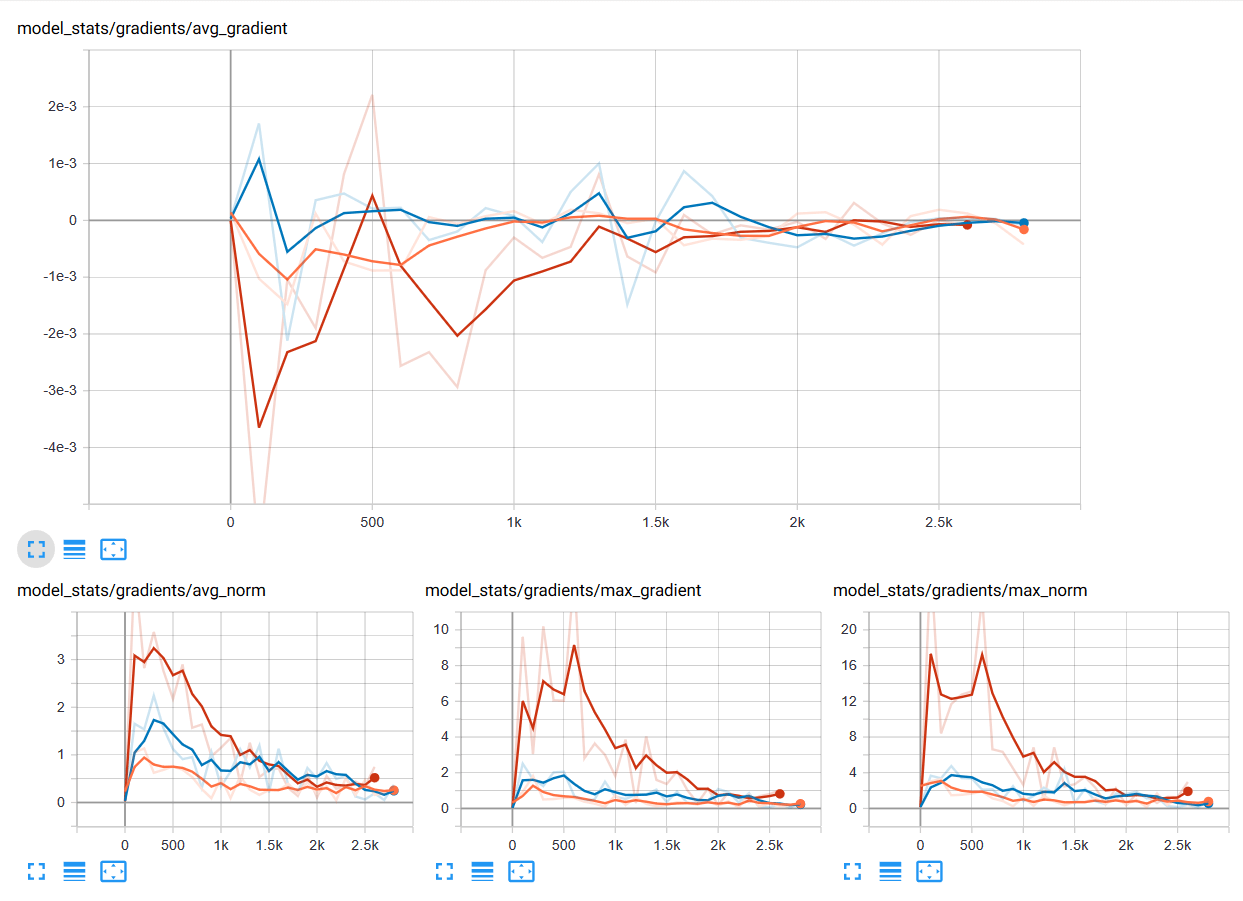
เรามาถึง Activation Function ep.3 เรื่อง ReLU Function ซึ่งเป็นฟังก์ชันที่นิยมใช้ในการเทรน Deep Learning มากที่สุดในปัจจุบัน เมื่อเราดูโครงสร้างภายในโมเดล Deep Neural Network ชื่อดังสมัยใหม่ ก็จะเห็นแต่ ReLU เต็มไปหมด แล้ว ReLU มีดีตรงไหน ต่างกับ Sigmoid และ Tanh อย่างไร เราจะมาเรียนรู้กัน