ในการประกาศฟังก์ชัน รายการ Parameter คือ การระบุว่า ฟังก์ชันนั้นจะรับ Argument อะไรบ้าง ในการเขียนโปรแกรม เราอาจจะไม่ได้คิดครอบคลุมในทุกเคสที่เป็นไปได้ทั้งหมด ในบางครั้งเราอาจจะอยากเปิดช่องไว้สำหรับ Argument ที่จะถูกใช้ในอนาคต เราสามารถทำได้โดยใช้ args, kwargs
Category Archives: Programming Language
Partial Function คืออะไร สอนเขียน Partial Function ตัวอย่างการใช้งาน functools.partial ในภาษา Python – Python ep.8
Partial Function คือ การสร้างฟังก์ชันใหม่ ขึ้นมาจากฟังก์ชันที่มีอยู่ โดย Fix Parameter ส่วนหนึ่งไว้ ทำให้เราได้ฟังก์ชันใหม่ที่ต้องการ Parameter น้อยลง ทำให้ Signature ของฟังก์ชันดูเรียบง่ายขึ้นกว่าเดิม
Lambda Expression คืออะไร สอนเขียน Anonymous Function ตัวอย่างการใช้งาน Lambda Function ในภาษา Python – Python ep.7

Lambda Expression คือ การประกาศฟังก์ชันเล็ก ๆ ที่สร้างขึ้นมาเฉพาะกิจ ในภาษา Python เป็น Anonymous Function คือ ฟังก์ชันนิรนาม ที่ประกาศโดยไม่ได้ตั้งชื่อ การไม่ได้ประกาศฟังก์ชันอย่างเต็มรูปแบบ ความกระชับของโค้ด และการไม่ได้ตั้งชื่อ ทำให้มีข้อดี เหมาะกับใช้ซ้อนในฟังก์ชั่นอื่น
Callback Function คืออะไร สอนเขียน Callback ฟังก์ชั่น ตัวอย่างการใช้งาน Callback ในภาษา Python – Python ep.6

ในภาษา Python เราสามารถส่งโค้ดเป็น Parameter ไปให้ฟังก์ชันอื่นเรียก เมื่อเกิดเหตุการณ์บางอย่าง เรียกว่า Callback การที่เราส่งโค้ดฟังก์ชันอะไรก็ได้ ไปให้คนอื่นเรียกเวลาที่เกิดเหตุการณ์อะไรสักอย่าง ทำให้เราสามารถกำหนดพฤติกรรมตอบสนองต่อเหตุการณ์นั้น ได้อย่าง Dynamic
Categorize การเตรียมข้อมูลหมวดหมู่ Categorical Data ด้วย One-Hot Encoding, Map ก่อนเทรน Machine Learning – Preprocessing ep.3
นอกเหนือจากข้อมูลตัวเลข Cardinal ค่าต่อเนื่อง (Continuous) เราจะพบ Feature ที่เป็นข้อมูลค่าไม่ต่อเนื่อง (Discrete) ในรูปแบบตัวเลขแบบ Ordinal, Nominal หรือข้อความ คือ มีค่าที่เป็นไปได้จำกัด ระบุว่าอยู่หมวดหมู่ไหน เช่น วันในสัปดาห์ 1 จันทร์, 2 อังคาร, 3 พุธ, … คือ 1 ใน 7 ค่าเท่านั้น เราจะไม่สามารถทำ Rescale, Normalize แบบใน ep 2 ได้ แล้วเราจะเตรียมข้อมูลชนิดนี้อย่างไรดี ถึงจะป้อนให้ Machine Learning ใช้เทรนได้
Normalization คืออะไร ปรับช่วงข้อมูล Feature Scaling ด้วยวิธี Normalization, Standardization ก่อนเทรน Machine Learning – Preprocessing ep.2
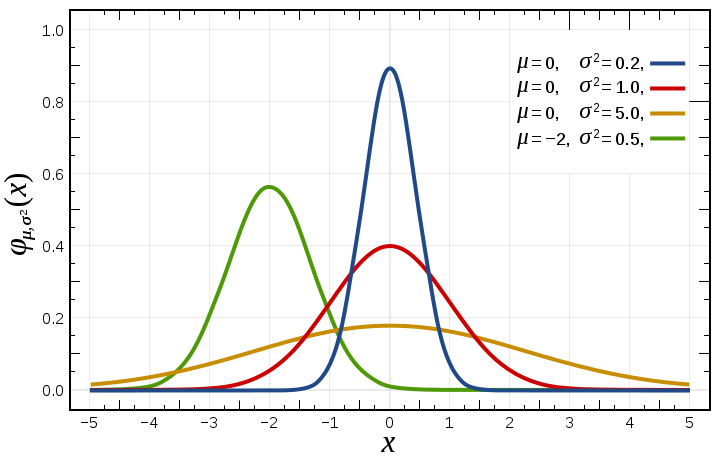
การทำ Feature Scaling คือ วิธีการปรับช่วงขอบเขตของข้อมูลชนิดตัวเลข Cardinal แต่ละ Feature (Field) ให้อยู่ในช่วงเดียวกัน ที่เหมาะกับการนำไปประมวลผลต่อ เข้าสูตรคำนวณได้ง่าย เช่น ช่วง [0, 1] หรือ [-1, 1] ได้ผลลัพธ์อยู่ในช่วงที่กำหนด เรียกว่า Data Normalization นิยมทำในขั้นตอน Preprocessing จัดเตรียมข้อมูล ก่อนป้อนให้โมเดลใช้เทรน
Preprocessing คืออะไร สอนจัดการข้อมูลขาดหาย Missing Value วิธีเติมข้อมูลแทนค่า Null, NA, NaN ก่อนป้อนโมเดล เทรน Machine Learning – Preprocessing ep.1

จาก ep ก่อน ที่เราสอนเรื่อง ใช้ Deep Neural Network วิเคราะห์ข้อมูลแบบ Structure หรือข้อมูลแบบตาราง Tabular Data จะมีงานสำคัญที่ต้องทำก่อนเทรน คือการ Preprocessing จัดเตรียมข้อมูล ซึ่งมีหลายอย่าง เช่น Fillna, Normalize, Categorize, Clipping, Binning, Feature Engineering ต่าง ๆ , etc. ใน ep นี้เราจะมาเรียนรู้กันเรื่อง การจัดการกับข้อมูลไม่ครบ วิธีเติมค่าที่ขาดหายไป หรือ Null
ทดสอบ Metrics ของ Neural Network ด้วยข้อมูลจาก Validation Set ระหว่างการเทรน Machine Learning – Neural Network ep.8
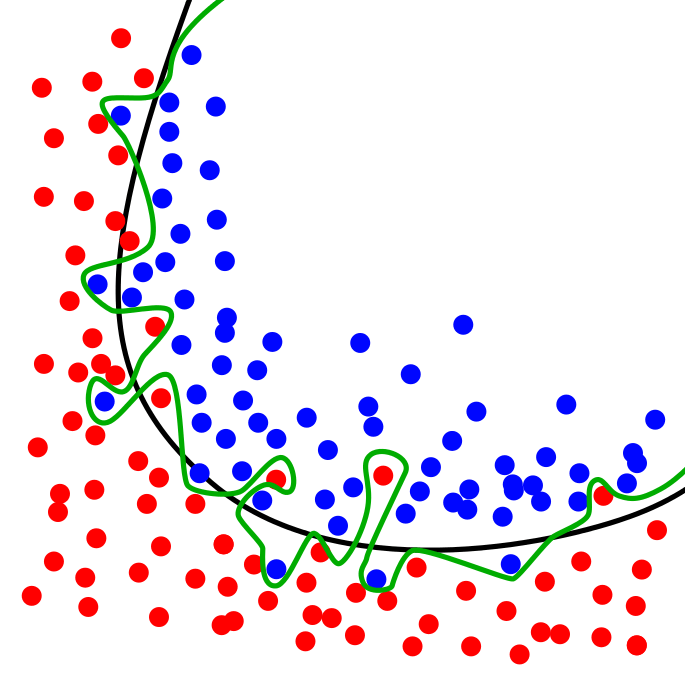
ในการเทรน Machine Learning การทดสอบว่าโมเดล Neural Network ทำงานเป็นอย่างไร ที่ถูกต้องเราไม่ควรเทสกับข้อมูล ใน Training Set ที่เราป้อนให้โมเดลในขณะเทรน เพราะจะทำให้ไม่ได้ค่าที่แท้จริง ถ้าโมเดลใช้วิธีจำข้อสอบ เรียกว่า Overfit เมื่อเทสแล้วจะได้คะแนนสูงผิดปกติ ที่ถูกคือ เราควรเทสกับข้อมูลที่โมเดลไม่เคยเห็นมาก่อน ใน Validation Set ที่เรากันเอาไว้ก่อนหน้าที่จะเริ่มต้นเทรน
สับไพ่ข้อมูล DataLoader ด้วย Random Sampler และ Collate ป้อนโมเดล เทรน Machine Learning – Neural Network ep.7

ในแต่ละ Epoch ของการเทรน Machine Learning สอนโมเดล Deep Neural Network เราไม่ควรป้อนข้อมูลที่เรียงลำดับเหมือนกันทุกครั้งให้โมเดล ใน ep นี้เราจะมาสร้าง DataLoader เวอร์ชันใหม่ ที่จะสับไพ่ข้อมูลตัวอย่างก่อนป้อนให้โมเดล เป็นการลดการจำข้อสอบของโมเดล ช่วยให้โมเดล Generalization ได้ดีขึ้น ลด Variance ของโมเดล
Refactor สร้าง Optimizer สำหรับอัพเดท Parameter ของ Neural Network ในการเทรน Deep Learning – Neural Network ep.6
ใน ep นี้เราจะมา Refactor Model สร้าง Module, Parameter และ Optimizer เป็น Abstraction ในจัดการการอัพเดท Parameter ของโมเดล ด้วยอัลกอริทึมต่าง ๆ เพื่อลดความซับซ้อน ของ Training Loop ทำให้การเทรน Neural Network ยืดหยุ่นขึ้น เราจะใช้โค้ดจาก Neural Network ep 5 เป็นโค้ดเริ่มต้น นำมา Refactor ต่อ