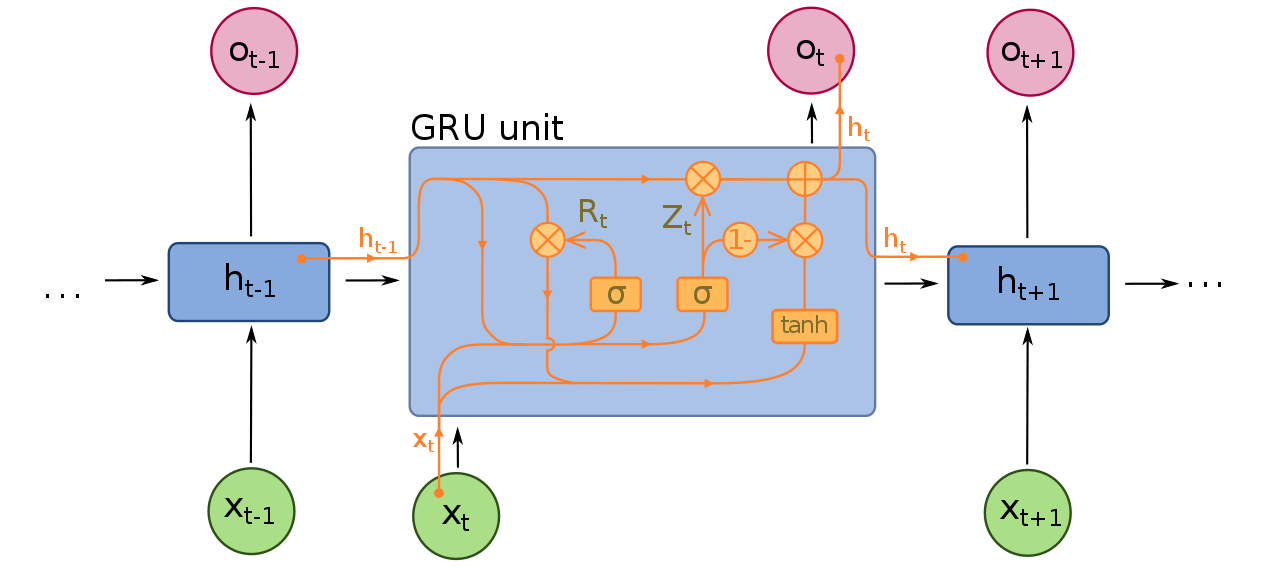
ใน ep นี้เราจะมาสร้าง Artificial Neural Network แบบ Recurrent Neural Network (RNN) กันแต่ต้น ด้วยภาษา Python เริ่มตั้งแต่ ปัญหาว่าทำไมต้องมี RNN พื้นฐานแนวคิด ศึกษาการทำงานของ RNN แบบง่าย ข้อดี ข้อเสีย แล้วพัฒนาโมเดล ปรับปรุง แก้ไขข้อจำกัดของโมเดล RNN แต่ละแบบ ไปจนถึง Gated Recurrent Unit (GRU)
Category Archives: Python
Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย AWD_LSTM Deep Neural Network เทรนแบบ ULMFiT Transfer Learning – NLP ep.8
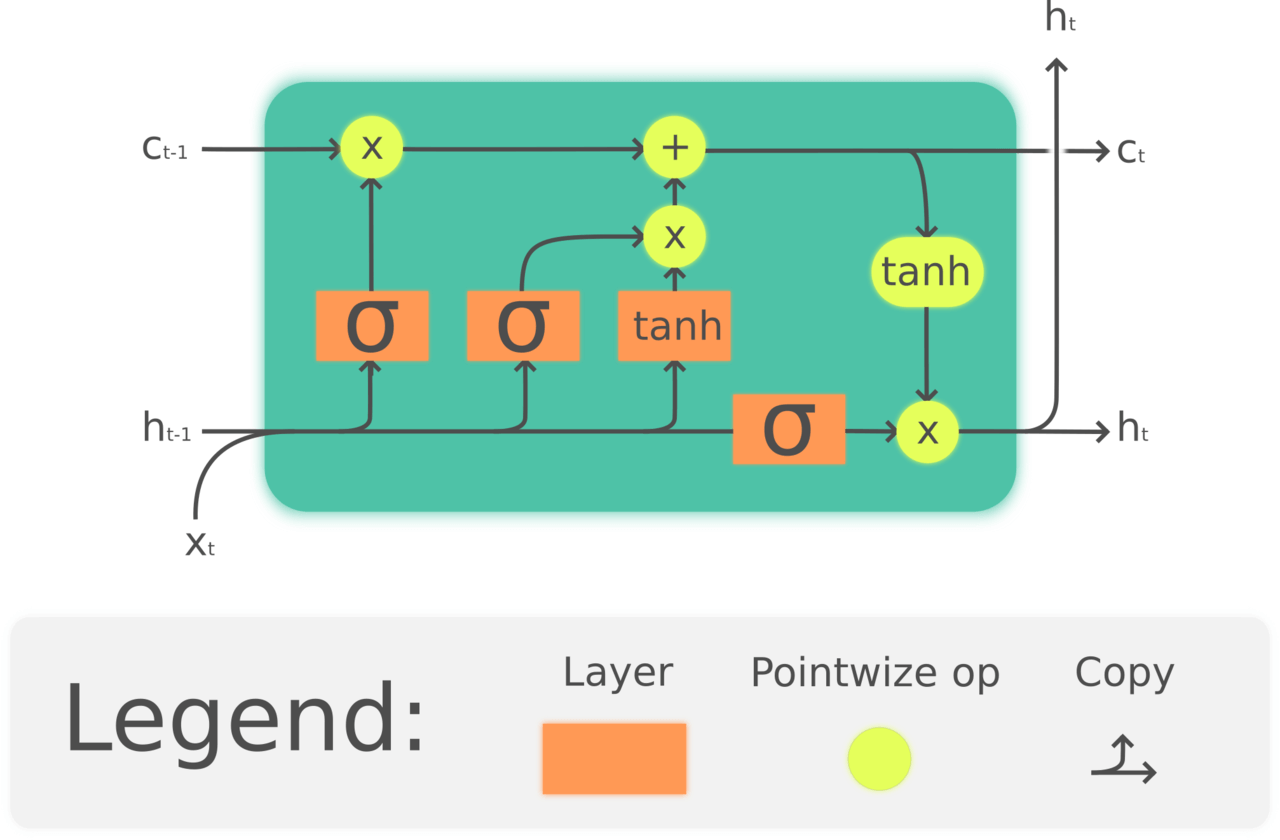
ใน ep ที่แล้วเราใช้ Naive Bayes และ Logistic Regression ที่เป็นอัลกอริทึมที่เป็นที่นิยมก่อนยุค Deep Learning แต่ใน ep นี้เราจะเปลี่ยนมาใช้ Deep Neural Network แทนว่าจะมีประสิทธิภาพต่างกันอย่างไร
N-Gram คืออะไร Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แบบ N-Gram (Trigram, Bigram, Unigram) ด้วย Naive Bayes, Logistic Regression – NLP ep.6
ใน ep ที่แล้ว Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย Naive Bayes และ Logistic Regression เราใช้ 1 Token ต่อ 1 คำ เรียกว่า Unigram แต่ใน ep นี้ เราจะมาเรียนรู้ N-Gram ในงาน Sentiment Classification ด้วยอัลกอริทึมเดียวกัน ep ที่แล้ว
AI การแพทย์ วินิจฉัยโรคมะเร็งระยะลุกลาม (Metastatic Cancer) อัตโนมัติ จากรูปแผ่นสไลด์ดิจิตอล โดยใช้ Machine Learning, Deep Neural Network – Image Classification ep.6
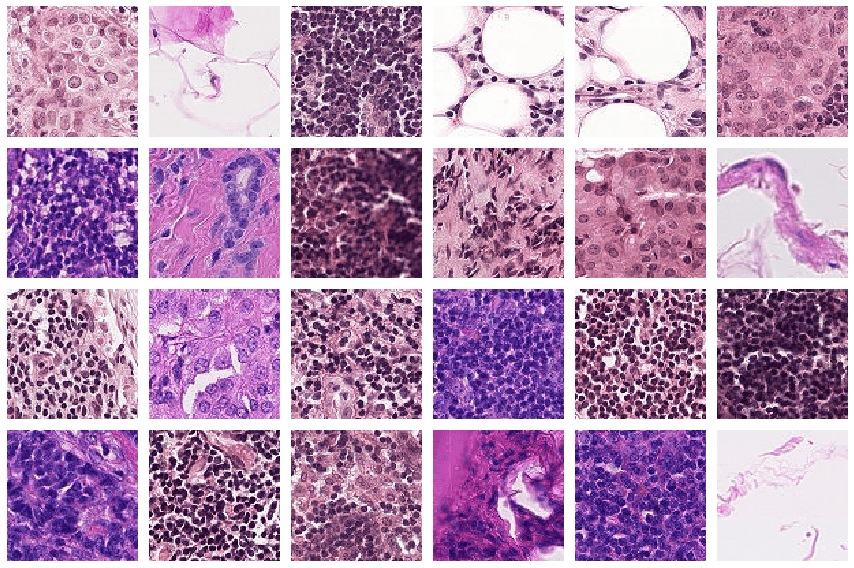
ใน ep นี้ เราจะมาสร้างโมเดลที่ใช้จำแนก โรคมะเร็งระยะลุกลาม Metastatic Cancer จากรูปภาพ Patch เล็ก ๆ ของ Whole Slide Imaging ที่ตัดมาจาก Digital Pathology Scans รูปใหญ่
Mixup Data Augmentation และ Label Smoothing คืออะไร ใน Machine Learning – Regularization ep.3

จากใน ep เรื่อง AI จำแนกรูปภาพ Image Classification หมา แมว 37 สายพันธุ์ ใน ep นี้เราจะมาเรียนรู้เทคนิคเพิ่มเติม ในเรื่อง Data Augmentation คือ Mixup และ Loss Function คือ Label Smoothing เพื่อแก้ปัญหาบางอย่างในการเทรนโมเดล Machine Learning ให้มีประสิทธิภาพดีขึ้น
Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย Naive Bayes และ Logistic Regression – NLP ep.5
ใน ep นี้ เราจะใช้ความรู้จาก ep ก่อน ในการสร้าง Term-Document Matrix ด้วย CountVectorizer ด้วยข้อมูลรีวิวหนัง IMDB แล้วนำ Term-Document Matrix ที่ได้ มาวิเคราะห์ Sentiment Classification ว่าเป็นรีวิวแง่บวก หรือแง่ลบ (positive/negative) ด้วยเทคนิค Naive Bayes และ Logistic Regression
สอนสร้าง Word Cloud ภาษาไทย ด้วย Python ใน Jupyter Notebook / Google Colab

ใน ep นี้เราจะมาเรียนรู้วิธีสร้างภาพ Tag Cloud ภาษาไทย สวย ๆ ด้วยภาษา Python กันแบบง่าย ๆ เหมือนในภาพ Cover ของบล็อก ep ก่อน ๆ เช่น อักษรกรีก คำอ่านภาษาไทย และ สอนวิธี Contribute Open Source Software Project
Latent Semantic Analysis (LSA) คืออะไร Text Classification ด้วย Singular Value Decomposition (SVD), Non-negative Matrix Factorization (NMF) – NLP ep.4
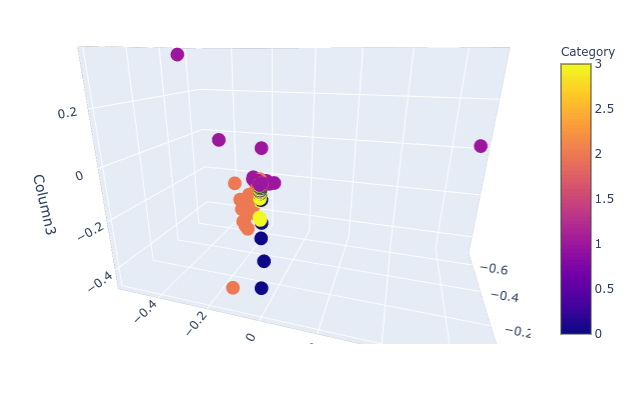
ใน ep นี้ เราจะมาเรียนรู้ งานจำแนกหมวดหมู่ข้อความ Text Classification ซึ่งเป็นงานพื้นฐานทางด้าน NLP ด้วยการทำ Latent Semantic Analysis (LSA) วิเคราะห์หาความหมายที่แฝงอยู่ในข้อความ โดยใช้เทคนิค Singular Value Decomposition (SVD) และ Non-negative Matrix Factorization (NMF)
Stemming คืออะไร Lemmatization คืออะไร Stemming และ Lemmatization ต่างกันอย่างไร – NLP ep.3

ตามหลักตามไวยากรณ์ภาษาอังกฤษ คำหนึ่งคำจะแปรไปได้หลายรูปแบบ เช่น organize, organizes, organized, organizing นอกจากนั้นคำยังสามารถแปลงเป็นกลุ่มคำ ที่มาจากรากศัพท์เดียวกันได้อีกหลายรูปแบบ เช่น democracy, democratic, democratization ในงาน NLP ถ้าเราต้องการค้นหาคำบางคำในกลุ่ม แล้วอยากให้ได้ผลลัพธ์ครอบคลุมทุกคำทั้งกลุ่ม แล้วเราจะทำอย่างไร
Stop Words คืออะไร ใน Natural Language Processing – NLP ep.2

Natural Language Processing (NLP) ในสมัยก่อนยุค Deep Learning เป็นที่นิยม นักวิจัยมักจะใช้วิธี Hand Engineer กับข้อมูล ในงาน NLP จะมีการเขียนโปรแกรมผูก Logic กฏระเบียบ ไวยากรณ์ ไว้หลายอย่างในโปรแกรม มีการตัดสินใจกำหนด Assumption / Bias หลายอย่าง หนึ่งในนั้นคือ Stop Words ตามรายการที่กำหนด สามารถตัดทิ้งได้ ไม่สำคัญกับความหมายของเนื้อหา ทำให้ลดจำนวนคำศัพท์ ลดความซับซ้อนของโปรแกรมลง