ใน ep นี้ เราจะใช้ความรู้จาก ep ก่อน ในการสร้าง Term-Document Matrix ด้วย CountVectorizer ด้วยข้อมูลรีวิวหนัง IMDB แล้วนำ Term-Document Matrix ที่ได้ มาวิเคราะห์ Sentiment Classification ว่าเป็นรีวิวแง่บวก หรือแง่ลบ (positive/negative) ด้วยเทคนิค Naive Bayes และ Logistic Regression
Naive Bayes Classifier คืออะไร
Naive Bayes Classifier คือ Classifier ด้วยความน่าจะเป็น Probability บนพื้นฐานของ ทฤษฎีของเบย์ (Bayes’ Theorem) เป็นโมเดลแบบง่าย ด้วยสมมติฐานที่ว่า แต่ละ Feature เป็นอิสระ ไม่ขึ้นต่อกัน
\( p(C_k \mid \mathbf{x}) = \frac{p(C_k) \ p(\mathbf{x} \mid C_k)}{p(\mathbf{x})} , {posterior} = \frac{\text{prior} \times \text{likelihood}}{\text{evidence}} \)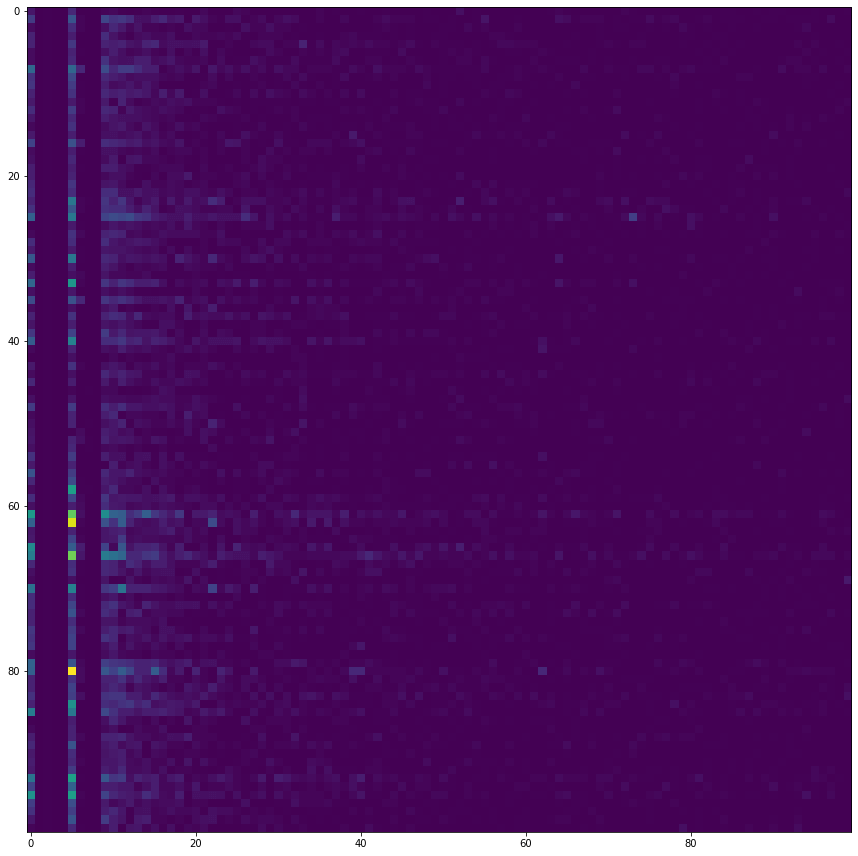
Logistic Regression คืออะไร
อ่านต่อ Logistic Regression คืออะไร

