ในยุคอินเตอร์เน็ต ยุคโซเชียลอย่างปัจจุบัน เราสามารถประยุกต์ใช้ Sentiment Analysis ได้อย่างหลากหลาย ไม่ว่าจะเป็นธุรกิจโรงหนัง วิเคราะห์ความรู้สึกลูกค้าหลังจากที่ดูหนัง, ภาคการตลาดวิเคราะห์ฟีดแบ็คของแคมเปญ, ภาคการเมืองใช้ในการวิเคราะห์ ความนิยม คะแนนเสียง, ภาคการเงินวิเคราะห์ข่าวธุรกิจสำหรับวางแผนลงทุน ไปจนถึง การแพทย์ วิเคราะห์ความรู้สึกผู้ป่วย
Sentiment Analysis คืออะไร
Sentiment Analysis คือ การวิเคราะห์ความรู้สึก วิเคราะห์อารมณ์จากข้อความ ไม่ว่าจะเป็นรีวิวหนัง รีวิวร้านอาหาร โพสเฟสบุ๊ค ทวิตเตอร์ แชท ว่าเป็นแง่บวก หรือแง่ลบ เป็นสาขาหนึ่งใน Natural Language Processing (NLP)
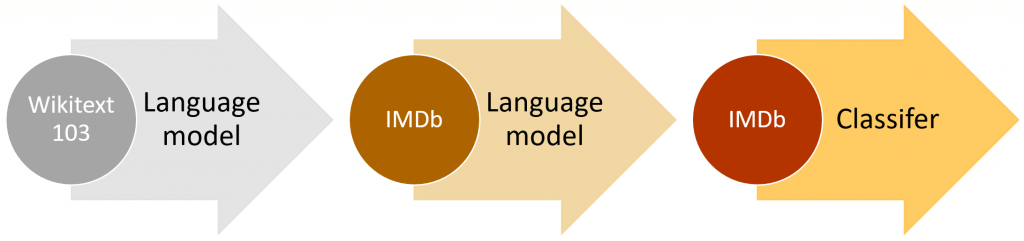
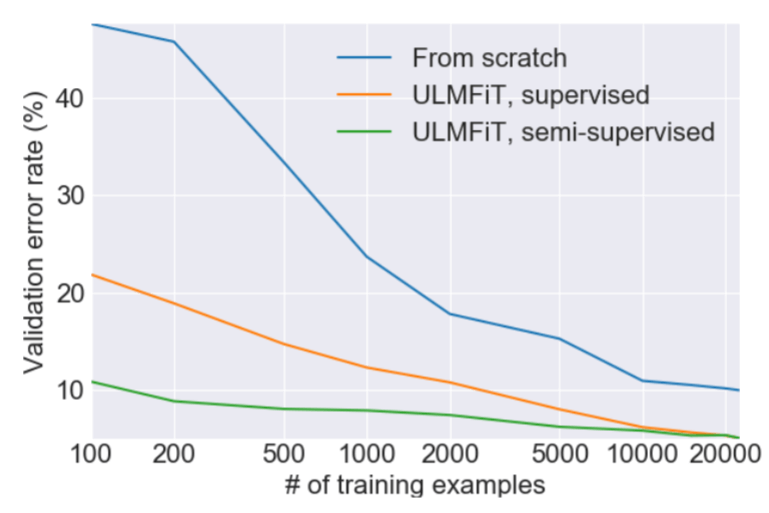
ในเคสนี้เราจะใช้วิธี ULMFiT ย่อมาจาก Universal Language Model Fine-tuning for Text Classification เป็นการนำ Transfer Learning ที่ใช้กันอย่างแพร่หลายใน Computer Vision มาประยุกต์ใช้กับ NLP ช่วยให้เทรนได้เร็วขึ้น ประสิทธิภาพดีขึ้น
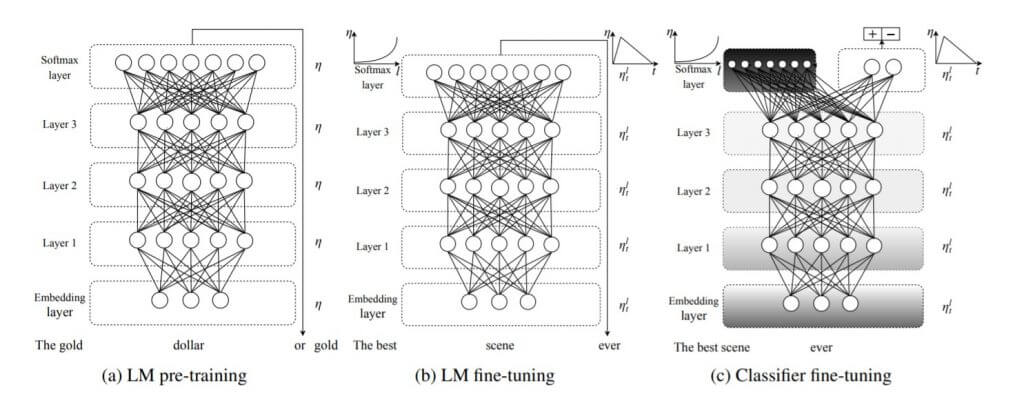
และที่สำคัญคือใช้ข้อมูลในการเทรนน้อยกว่า
Language Model คืออะไร
Language Model คือ โมเดลภาษา การเข้าใจภาษา บางทีต้องเข้าใจโลกของภาษานั้น ๆ ด้วย ตัวอย่างคือ สามารถเดาคำในช่องว่างได้ เช่น หมาตัวนี้สี…, แมนยูกำลังให้ความสนใจดาวยิงชาวสเปนอย่าง…, President Obama fought unsuccessfully to restrict gun …
เรามาเริ่มกันเลยดีกว่า
Credit
- https://www.imdb.com/title/tt4154796/
- http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html
- https://arxiv.org/abs/1801.06146

