ใน ep ก่อน ๆ เราได้เห็นตัวอย่างการนำ Machine Learning, Deep Learning มาประยุกต์ใช้งานเกี่ยวกับวิเคราะห์รูปภาพ วิเคราะห์ข้อความ ทั้งหมดถือว่าเป็นข้อมูลแบบ Unstructure Data แต่งานประมวลผลข้อมูลส่วนใหญ่ในปัจจุบันจะเป็น ข้อมูลแบบมีโครงสร้าง Structure Data เช่น ตาราง เป็นหลัก แล้วเราจะนำ Deep Learning มาประยุกต์ใชักับงานเหล่านี้อย่างไร
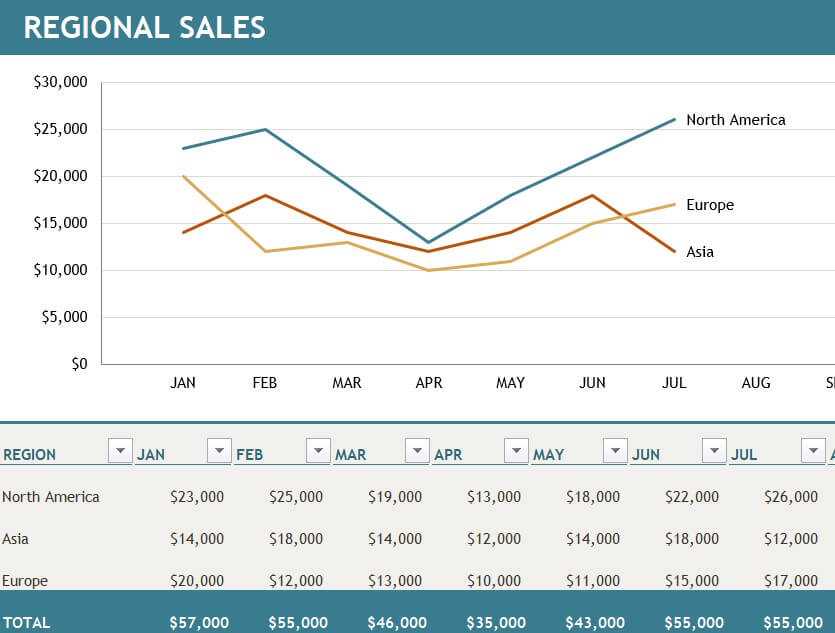
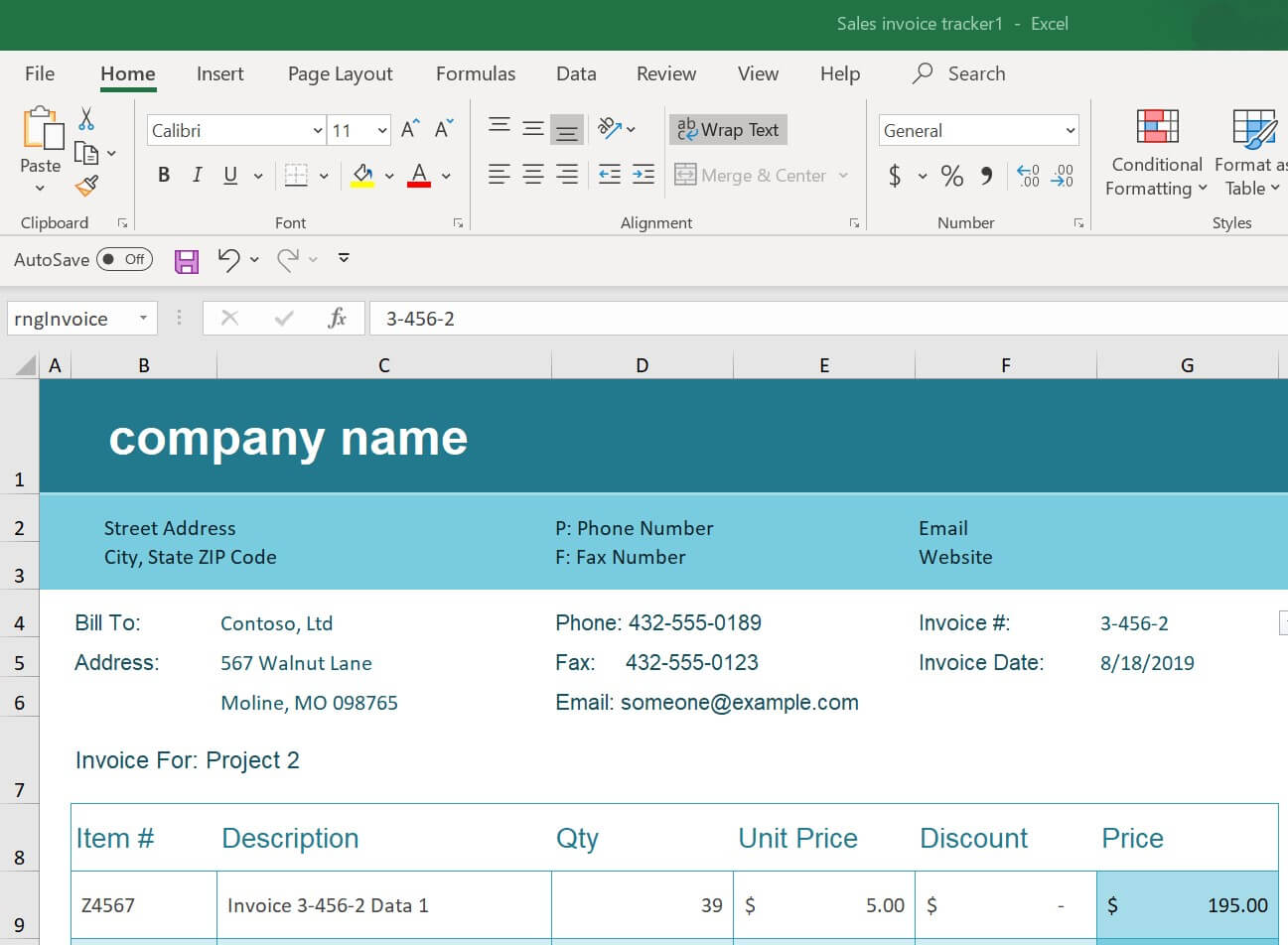
ตัวอย่างข้อมูลแบบตาราง ในภาคธุรกิจ