
จาก ep ที่แล้วที่เราเรียนรู้เรื่อง Feature Engineering แบบ Basic กันไปแล้ว ใน ep นี้เราจะมาศึกษาข้อมูลที่เราพบบ่อย ๆ ในการทำงานอีกเช่นกัน คือ ข้อมูลแบบ Time Series เราจะสอนโมเดล Machine Learning ให้เรียนรู้จากข้อมูล Time Series ได้อย่างไร ให้ Forecast พยากรณ์ยอดขายร้านขายยา Rossmann ได้ความแม่นยำมากที่สุด
และจำเป็นต้องใช้ Deep Neural Network แบบ Recurrent Neural Network (RNN) หรือไม่
Time Series
Time Series คือ ข้อมูลที่เปลี่ยนแปลงไปตามเวลา การจะใช้ข้อมูลแบบนี้ เราจะแบ่งเวลาออกเป็นช่วงเท่า ๆ กัน เช่น รายชั่วโมง รายวัน รายเดือน แล้วรวบรวมข้อมูลตามช่วงนั้น มาวิเคราะห์อดีต เพื่อทำนายอนาคตต่อไป เช่น อุณหภูมิเฉลี่ยแต่ละวัน อุณหภูมิสูงสุดแต่ละเดือน ยอดขายรายวัน ยอดขายรายสัปดาห์ จำนวนคนเข้าร้านรายชั่วโมง จำนวนคนเข้าร้านรายเดือน etc.
Dataset
ในเคสนี้เราจะใช้ Dataset ชื่อ Rossmann Store Sales จาก Kaggle

Rossmann เป็นเชนร้านขายยา ที่มีมากกว่า 3000 สาขาใน 7 ประเทศแถบยุโรป ผู้จัดการสาขามีหน้าที่ประเมินยอดขายรายวัน ล่วงหน้า ตั้งแต่วันรุ่งขึ้น ไปจนถึง 6 สัปดาห์ข้างหน้า ยอดขายของแต่ละสาขาจะมากขึ้นหรือน้อยลง ขึ้นอยู่กับหลายปัจจัย เช่น โปรโมชั่น คู่แข่ง วันหยุดโรงเรียน วันหยุดราชการ เทศกาลต่าง ๆ
ใน Dataset จะมีข้อมูลประวัติยอดขาย ระหว่างวันที่ 1 Jan 2013 – 31 July 2015 ของ 1115 สาขา ในประเทศเยอรมัน หน้าที่ของเราก็คือ ทำนายยอดขายใน Column Sales ใน Test Set
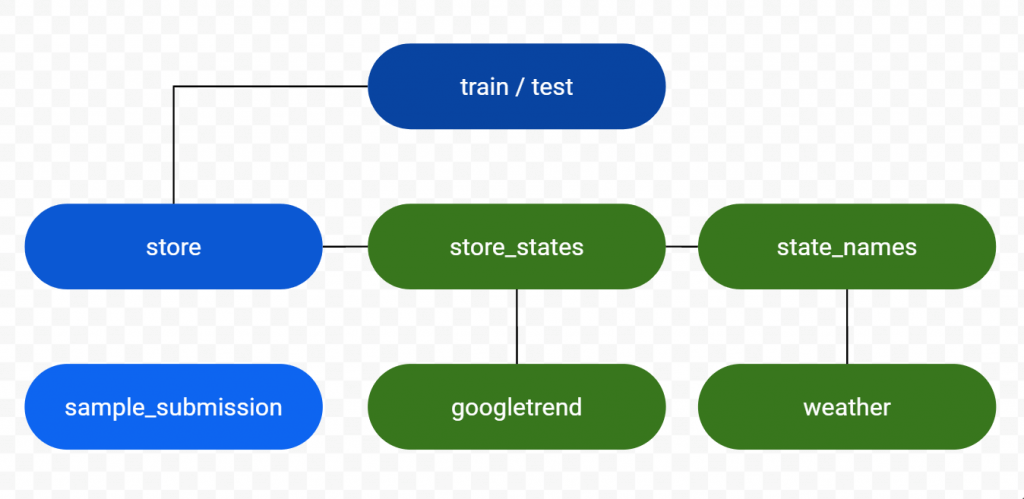
มีไฟล์ดังนี้
- train.csv – ข้อมูลสาขารายวัน และประวัติการขาย
- test.csv – ข้อมูลสาขารายวัน ไม่รวมยอดขาย
- sample_submission.csv – ตัวอย่างไฟล์สำหรับ Submit
- store.csv – ข้อมูลสาขา Master
ข้อมูลเพิ่มเติม
- state_names.csv
- googletrend.csv
- store_states.csv
- weather.csv
หมายเหตุ มีบางสาขากำลังปิด เพื่อ Renovate

