
จากใน ep ที่แล้ว เราได้ใช้งาน PyThaiNLP ตัดคำภาษาไทย ตัดข้อความยาว ๆ Tokenization ออกมาเป็น Token เรียบร้อยแล้ว ใน ep นี้ เราจะมาดูว่า แต่ละ Token นั่นสะกดถูกหรือไหม Spellchecker รวมไปถึงแนะนำ และแก้ไขให้ถูกต้อง Spelling Correction ก่อนที่จะนำไปป้อนให้โมเดลในงานวิเคราะห์ทางด้าน NLP ต่อไป
Tag Archives: Corpus
Latent Semantic Analysis (LSA) คืออะไร Text Classification ด้วย Singular Value Decomposition (SVD), Non-negative Matrix Factorization (NMF) – NLP ep.4
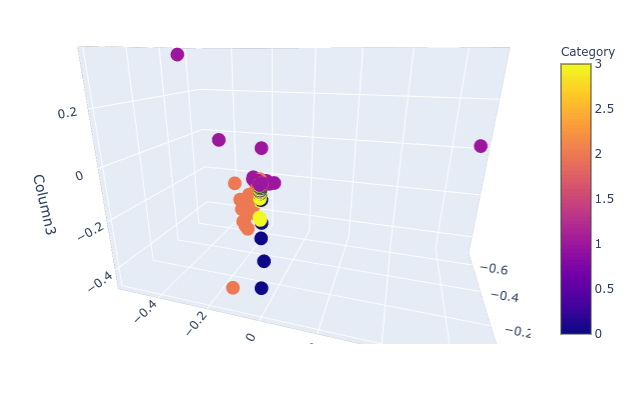
ใน ep นี้ เราจะมาเรียนรู้ งานจำแนกหมวดหมู่ข้อความ Text Classification ซึ่งเป็นงานพื้นฐานทางด้าน NLP ด้วยการทำ Latent Semantic Analysis (LSA) วิเคราะห์หาความหมายที่แฝงอยู่ในข้อความ โดยใช้เทคนิค Singular Value Decomposition (SVD) และ Non-negative Matrix Factorization (NMF)
Sentiment Analysis คืออะไร สอน Sentiment Analysis วิเคราะห์ความรู้สึก จากรีวิวหนัง IMDB ด้วย ULMFiT – Sentiment Analysis ep.1
ในยุคอินเตอร์เน็ต ยุคโซเชียลอย่างปัจจุบัน เราสามารถประยุกต์ใช้ Sentiment Analysis ได้อย่างหลากหลาย ไม่ว่าจะเป็นธุรกิจโรงหนัง วิเคราะห์ความรู้สึกลูกค้าหลังจากที่ดูหนัง, ภาคการตลาดวิเคราะห์ฟีดแบ็คของแคมเปญ, ภาคการเมืองใช้ในการวิเคราะห์ ความนิยม คะแนนเสียง, ภาคการเงินวิเคราะห์ข่าวธุรกิจสำหรับวางแผนลงทุน ไปจนถึง การแพทย์ วิเคราะห์ความรู้สึกผู้ป่วย
Natural Language Processing (NLP) คืออะไร รวมคำศัพท์เกี่ยวกับ Natural Language Processing (NLP) – NLP ep.1

การประมวลผลภาษาธรรมชาติ หรือ Natural Language Processing (NLP) คือ หนึ่งในสาขาของวิทยาศาสตร์คอมพิวเตอร์ ที่เกี่ยวกับปัญญาประดิษฐ์ Artificial Intelligence และภาษาศาสตร์คอมพิวเตอร์ Computational Linguistics เป็นศาสตร์ที่ศึกษาเกี่ยวกับการทำให้คอมพิวเตอร์สามารถสื่อสารโต้ตอบด้วยภาษาของมนุษย์ และทำให้คอมพิวเตอร์เข้าใจภาษามนุษย์มากขึ้น ตัวอย่าง เช่น Siri, Google Assistant และ Alexa ในการศึกษาเกี่ยวกับ NLP จะมีคำศัพท์ที่เกี่ยวข้องหลายคำ ตัวอย่างเช่น