ใน ep นี้ เราจะมาเรียนรู้ งานจำแนกหมวดหมู่ข้อความ Text Classification ซึ่งเป็นงานพื้นฐานทางด้าน NLP ด้วยการทำ Latent Semantic Analysis (LSA) วิเคราะห์หาความหมายที่แฝงอยู่ในข้อความ โดยใช้เทคนิค Singular Value Decomposition (SVD) และ Non-negative Matrix Factorization (NMF)
Singular Value Decomposition (SVD) คืออะไร
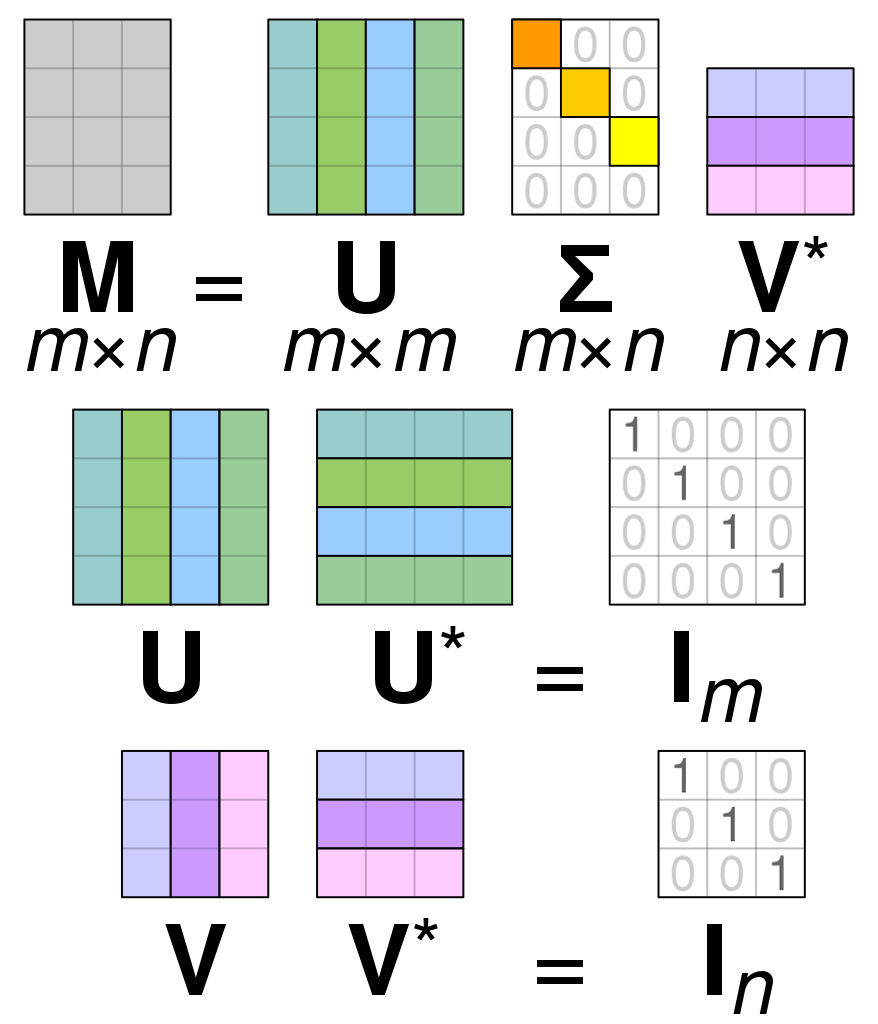
SVD เป็นวิธี Factorization ยอดนิยม SVD จะแปลง 1 Matrix ขนาดใหญ่ ออกมาเป็น 3 Matrix ขนาดเล็กกว่า ที่คูณกันแล้วได้เท่ากับ Matrix ต้นทาง
3 Matrix ใหม่ที่ได้ออกมา มีคุณสมบัติพิเศษบางอย่าง ทำให้เราสามารถนำมาใช้งาน วิเคราะห์ข้อมูลได้ดีขึ้น
SVD มีประโยชน์มาก ถูกนำไปประยุกต์ใช้ในหลายงาน เช่น
- Semantic Analysis
- Collaborative Filtering / Recommendations
- Calculate Moore-Penrose Pseudoinverse
- Data Compression
- Principal Component Analysis (PCA)
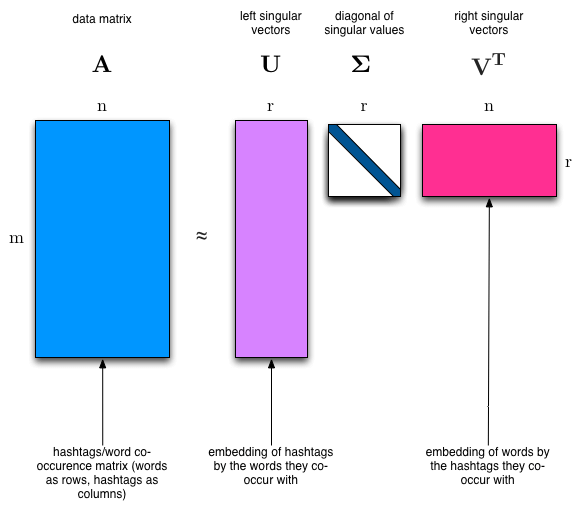
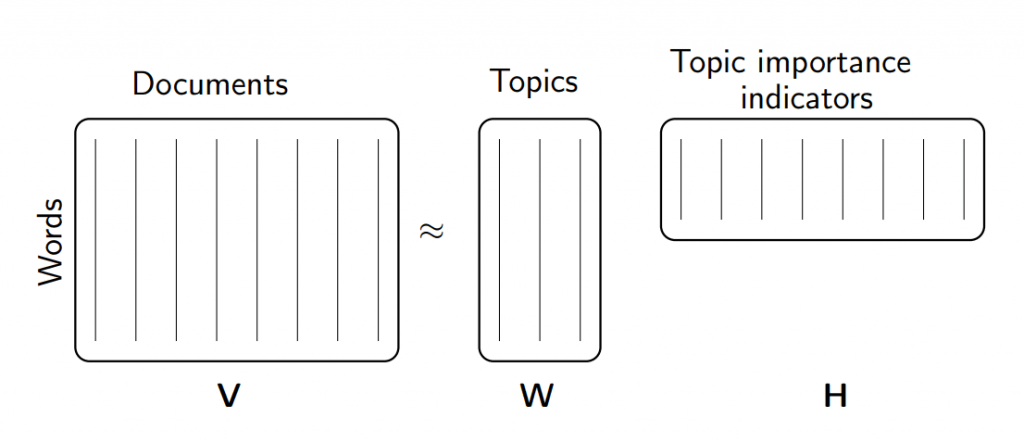
หา svd ของ Matrix ต้นฉบับ ชื่อ vectors ออกมาได้เป็น 3 Matrix ชื่อ U, s Vh
เปรียบเทียบ U คือ รายการ Embedding ของ Topic by ข้อความ, s คือ Scale ขนาดความสำคัญของ Topic by ข้อความ, Vh คือ รายการ Embedding ของ Vocab by Topic
แทนที่เราจะเปรียบเทียบ 2 ข้อความ ด้วยจำนวนคำศัพท์ในข้อความ ใน Term-Document Matrix ตรง ๆ ตอนนี้เรามี Abstraction เพิ่มขึ้นมาอีก 1 ตัวคือ Topic ให้เราใช้เปรียบเทียบ ว่า 2 ข้อความมีปริมาณ แต่ละ Topic ใกล้เคียง หรือแตกต่างกันอย่างไร
Non-negative Matrix Factorization (NMF) คืออะไร
แต่ SVD ก็มีปัญหาคือ มีค่าเป็นติดลบได้ ทำให้มีปัญหาต่อการตีความ จึงมี Matrix Factorization อีกหนึ่งวิธีที่เป็นที่นิยม คือ Non-negative Matrix Factorization (NMF) มาแก้ปัญหาค่าติดลบ ตามชื่อ คือ ผลลัพท์จะได้ Matrix ที่เป็นค่าบวกเท่านั้น
ข้อดีของ NMF คือ ใช้ง่าย ทำงานได้อย่างรวดเร็ว แต่มีข้อเสียคือ ผลลัพธ์เป็นค่าประมาณ ทำให้ไม่สามารถรวมกลับเป็น Matrix ต้นฉบับเหมือนเดิมได้เหมือน SVD และ เป็น NMF อัลกอริทึม เป็น Nondeterministic คือทำงานแต่ละครั้ง ผลลัพธ์อาจจะไม่เท่ากันก็ได้
แต่ข้อดีของค่าประมาณ คือ จัดการกับ Missing Value, ข้อมูลคุณภาพต่ำ ได้ดีกว่า

