
จาก ep ที่แล้ว Neural Machine Translation แปลภาษาฝรั่งเศส เป็นภาษาอังกฤษ ด้วย Sequence to Sequence RNN/GRU Model และ Attention ใน ep นี้ เราจะมาเรียนรู้เรื่อง NLP ในงาน Neural Machine Translation กันต่อ แต่แทนที่จะใช้ RNN เหมือน ep ก่อน ๆ ใน ep นี้เราจะใช้สถาปัตยกรรมใหม่ ที่เรียกว่า Transformer ที่เน้น Attention แทนการใช้ RNN ว่าจะมีประสิทธิภาพเพิ่มขึ้นอย่างไร
Transformer คืออะไร ใน Machine Learning
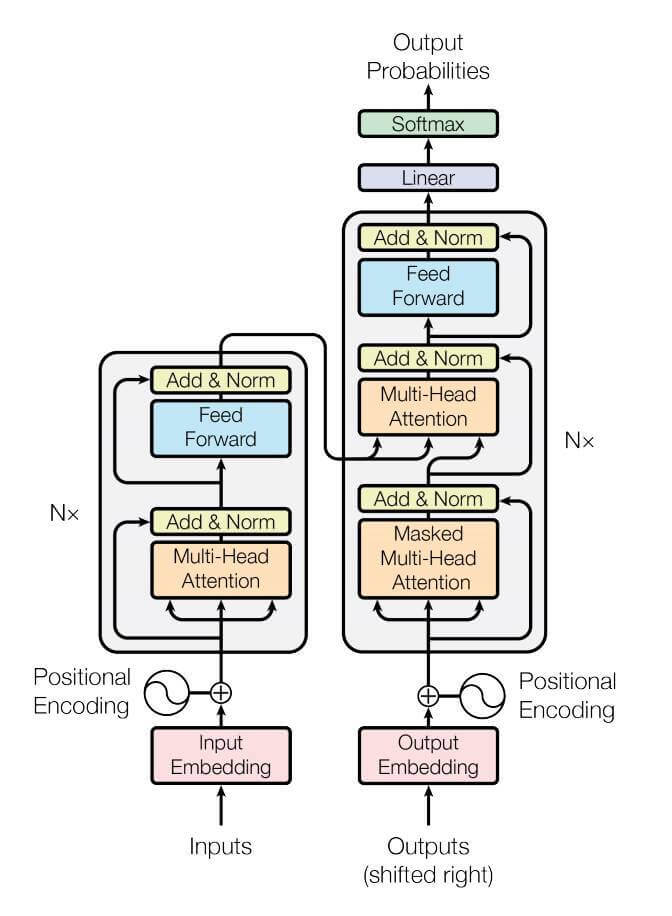
จาก ep ที่แล้ว ที่เรานำ Attention Mechanism มาประยุกต์ใช้ เพื่อประสิทธิภาพให้กับโมเดล Sequence to Sequence RNN ในงาน Neural Machine Translation ซึ่งเป็นหนึ่งในงานด้าน NLP ได้เป็นอย่างดี แต่ RNN ก็ยังมีปัญหาในตัวเอง คือ ไม่ GPU Friendly และ Vanishing Gradient เมื่อเจอประโยคยาว ๆ จึงมีการออกแบบ LSTM, GRU เพื่อแก้ปัญหานี้ รวมถึงใช้ CNN เข้ามาช่วยในโมเดล แต่ก็ยังแก้ได้ไม่ดีเท่าที่ควร
ในปี 2017 นักวิจัยจาก Google ได้นำเสนอ Paper ชื่อว่า Attention Is All You Need ไอเดียหลักคือเลิกใช้ RNN, CNN ไปเลย ใช้แต่ Fully-Connected Layer + Attention เท่านั้น ก็สามารถทำประสิทธิภาพได้ดีกว่า Seq2Seq RNN อย่างมาก โดยเทรนได้เร็วกว่า ใช้ทรัพยากรน้อยกว่า และตีความการทำงานภายในได้ง่ายขึ้น
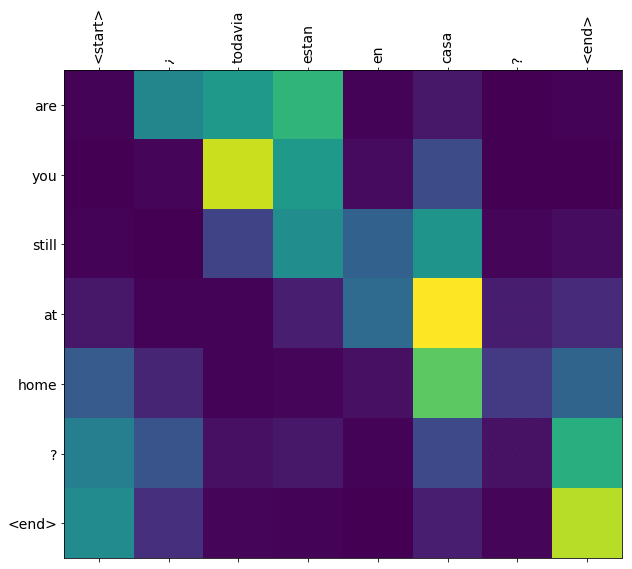
Transformer ประกอบด้วยส่วนต่าง ๆ ดังนี้
Multi-Head Attention
จาก ep ที่แล้วที่เรานำเทคนิค Attention มาประยุกต์ใช้ เพื่อเพิ่มประสิทธิภาพให้กับโมเดล สามารถเรียนรู้ และเลือกที่จะสนใจ Input เป็นบางส่วนได้
Multi-Head Attention คือ ออกแบบให้โมเดลสามารถมีหลาย ๆ Attention ได้พร้อม ๆ กัน โดยเอาหลาย ๆ Attention มาต่อขนานกันไป

ตัวอย่างเช่น ในการแปลภาษา ขณะที่แปลคำบางคำ เราอาจจะต้องคำนึงถึงหลายอย่างพร้อม ๆ กัน เช่น ใคร David/Susan, ทำอะไร will do/did, ทำกับใคร them/him, คนทำเป็นเพศอะไร he/she, ทำเวลาไหน tomorrow/yesterday, คำนี้พูดถึงใคร/อะไร it/guys/one
Self-Attention Mechanism
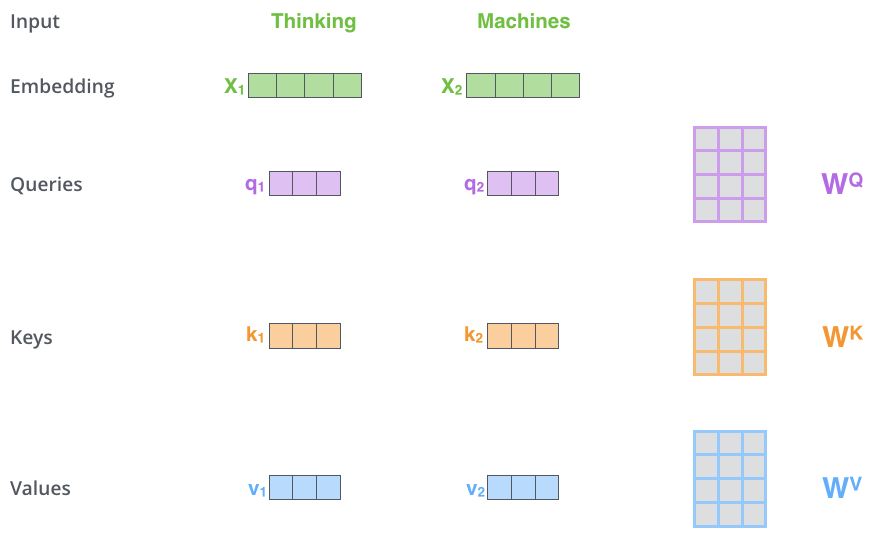
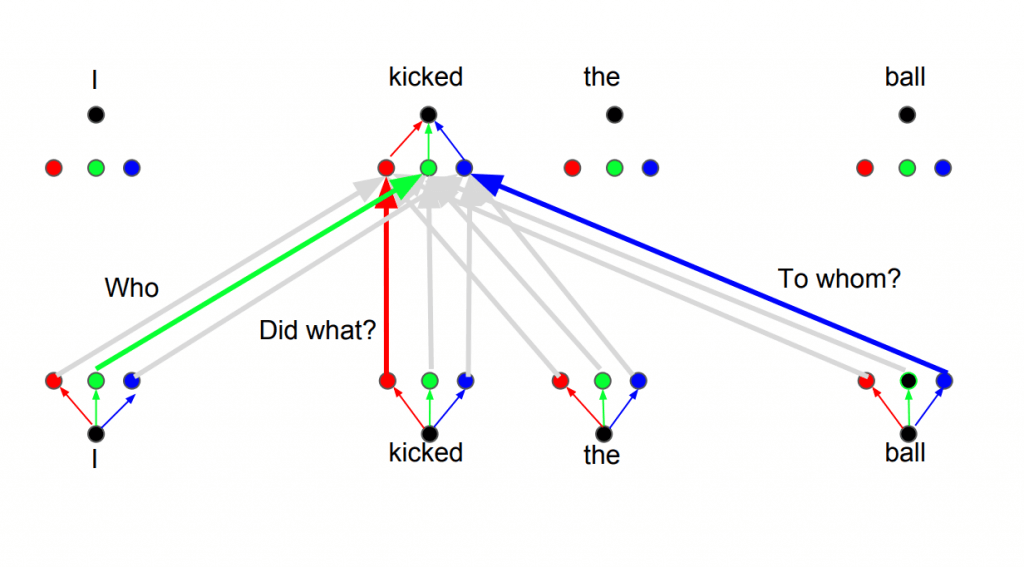
แนวคิดของ Self-Attention คือ นำคำทุกคำในประโยคมาเปรียบเทียบกันเอง ให้โมเดลเรียนรู้ และเลือกเอง ว่าจะสนใจคำไหน เมื่อไร ด้วยการแปลง Input เป็น 3 Vector คือ
- Q Query เอาไว้ Match กับ Key
- K Key เอาไว้ Match กับ Query
- V Value คือค่าที่จะนำไป Attend จากสัดส่วน Score ผลลัพธ์การ Match ของสอง Vector บน
การคำนวน Vector Q Query, K Key และ V Value จะคำนวนจากการคูณ Input เข้ากับ Weight Matrix WQ, WK, WV หรือก็คือ Linear Layer ธรรมดานี่เอง โดย Weight เหล่านั้นก็จะเป็น Learned Parameter ที่โมเดลจะเรียนรู้ขึ้นมาเอง จากการเทรนด้วย Gradient Descent ตามปกติ
ยังไม่มีการพูดถึง Language Model ในเคสนี้
Feed Forward
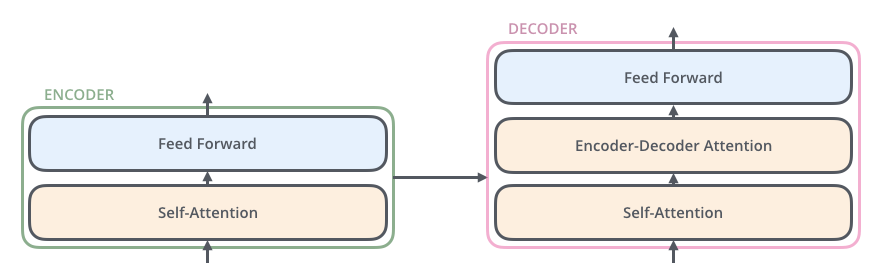
Feed Forward ของ Transformer ในเคสนี้ คือ Fully-Connected Layer ธรรมดา ๆ (สีฟ้า) ไม่ใช่ RNN หรือ CNN ประกอบด้วย
- Linear Layer + ReLU
- Layer Norm ทำหน้าที่เหมือน BatchNorm
- Skip Connection เพื่อให้ Gradient Flow ได้ดีเหมือน ResNet
Positional Embeddings
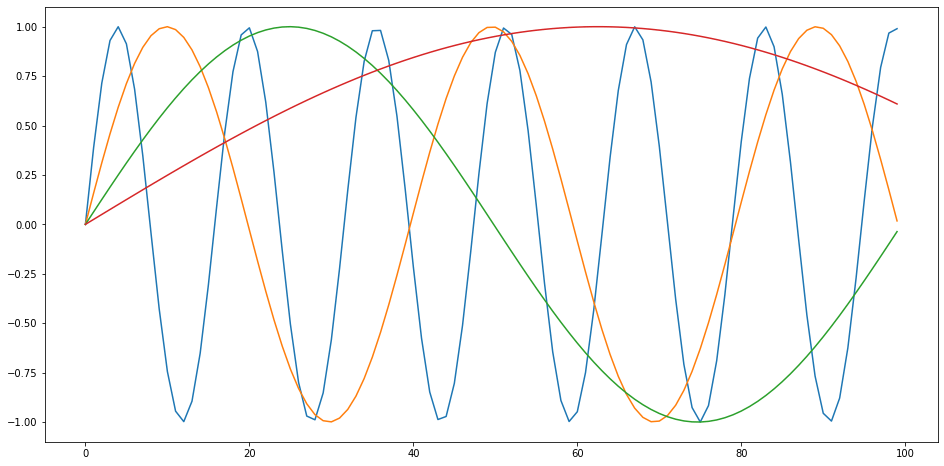
เมื่อเราใช้ Fully-Connected Layer แทน RNN ข้อมูลที่เข้าโมเดลแทนที่จะ Feed เข้า Time Step ละ Token ก็จะเข้าทีเดียวทั้งประโยค
การ Feed ข้อมูลให้โมเดลแบบทีเดียวเป็นก้อนแบบนี้ เราจะสูญเสียความหมายของ ลำดับของข้อมูลไป ซึ่งจะแก้ด้วยการบวก Embedding ใส่ Position เข้าไปใน Embedding ของคำศัพท์
ใน Paper นำเสนอหลายวิธีในการ Positional Encoding ทั้งแบบ Absolute และ Relative ตั้งแต่ ใช้ Learned Parameter และ ค่า Fixed ด้วยฟังก์ชันประเภท Sinusoid ด้วย Sine, Cosine
ปรากฎว่าผลลัพธ์ประสิทธิภาพพอ ๆ กัน แต่ข้อดีของ Sinusoid คือ ประมวลผลเร็วกว่า และยาวได้ไม่จำกัด ถ้าเป็น Learned Parameter จะมีปัญหากับประโยคยาว ๆ ที่มีน้อยใน Training Set ทำให้โมเดล Learn ไม่ได้ดีเท่าที่ควร
Masking

ใน Attention Layer ใน Decoder เราจะใช้ Mask ในการป้องกันไม่ให้โมเดลสนใจ Input ในบาง Step เช่น ใน Step ที่ Input เป็น Padding เป็นต้น
และที่สำคัญกว่านั้นเราจะใช้ Mask ในการป้องกันไม่ให้โมเดลเห็นข้อมูลที่ยังไม่ควรเห็น ไม่งั้นก็จะเห็นคำตอบก่อนได้ เหมือนเป็นการโกงข้อสอบ

