ใน ep ที่แล้วเราใช้ Naive Bayes และ Logistic Regression ที่เป็นอัลกอริทึมที่เป็นที่นิยมก่อนยุค Deep Learning
แต่ใน ep นี้เราจะเปลี่ยนมาใช้ Deep Neural Network แทนว่าจะมีประสิทธิภาพต่างกันอย่างไร
Universal Language Model Fine-tuning (ULMFit)
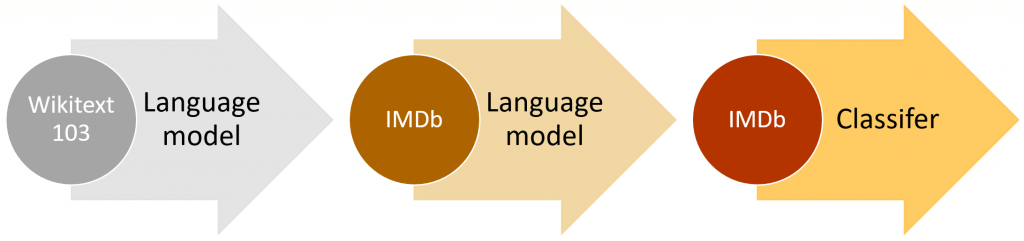
ในการเทรน เราจะไม่เทรนแต่ต้น โดย Initialize Weight ด้วยค่า Random หรือ Kaiming แต่เราจะใช้ Transfer Learning จาก Language Model ที่เทรนกับ Corpus ขนาดใหญ่กว่ามาก่อน เช่น WikiText-103
แล้ว Fine-Tuned Language Model นั้นเข้ากับ กับภาษา สำนวน คำศัพท์ ใน IMDB
เมื่อได้ Language Model ที่ Fine-Tuned กับภาษาของ IMDB เรียบร้อยแล้ว เราจึงนำส่วนของ Encoder มาสร้าง Sentiment Classifier ต่อ
กระบวนการนี้ เรียกว่า ULMFit หรือ Universal Language Model Fine-tuning ที่จะลดเวลาการเทรนโดยรวม และเพิ่มประสิทธิภาพการทำงานของโมเดล
AWD_LSTM Model Architecture
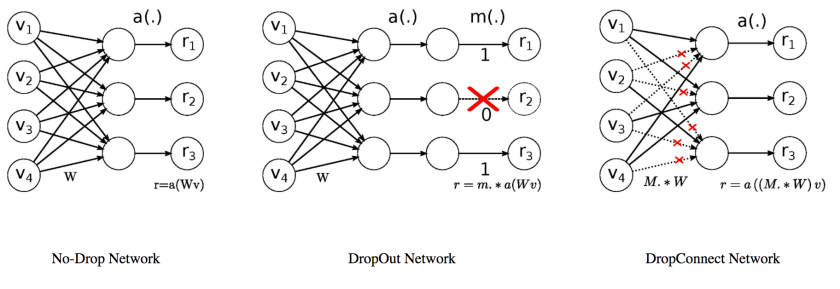
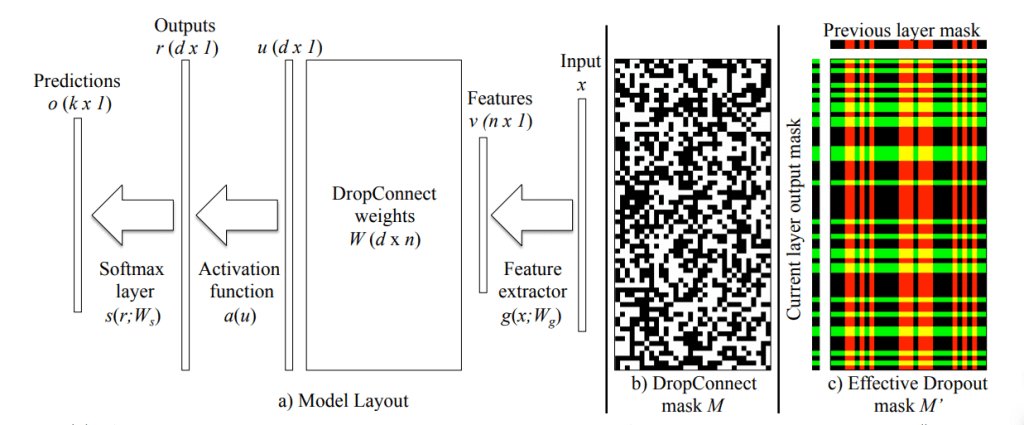
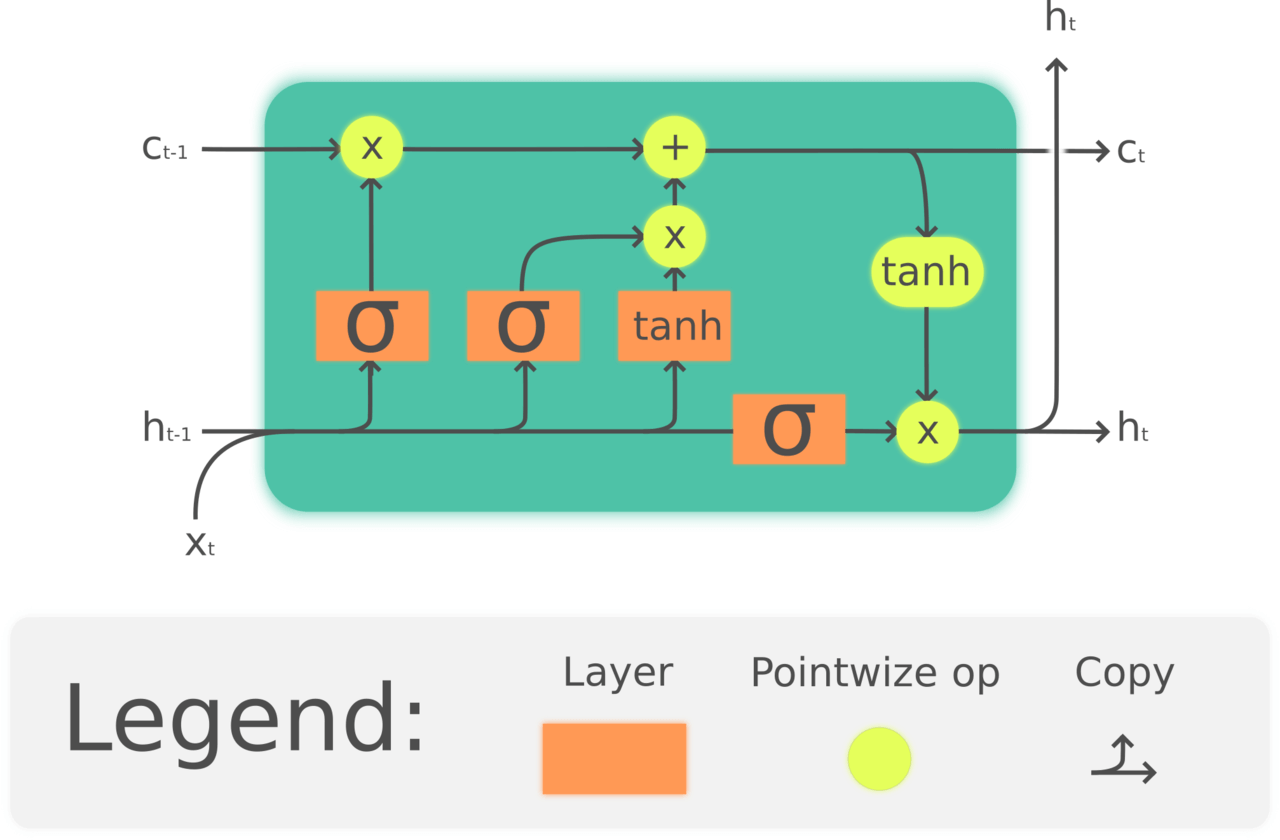
AWD_LSTM เป็น LSTM / Recurrent Neural Network (RNN) แบบหนึ่ง ที่มีการใช้ DropOut / DropConnect หลากหลายแบบภายในส่วนต่าง ๆ ของโมเดล อย่างชาญฉลาด จะอธิบายต่อไป