
ใน ep นี้เราจะมาศึกษาอีก Concept นึงที่สำคัญของ NLP คือ Language Model หรือ โมเดลของภาษา ซึ่งถ้าโมเดลของเรามีความสามารถที่จะเข้าใจภาษาโดยภาพรวมได้ดีระดับหนึ่งแล้ว ก็จะส่งผลให้โมเดลนั้นทำงานเฉพาะทาง เช่น Classification, Sentiment Analysis, Machine Translation, Question-Answer ได้ดีขึ้นไปด้วยในตัว
Tag Archives: token
Python ตัดคำภาษาไทย ด้วย PyThaiNLP API ตัดคำ Word Tokenize ภาษาไทย ตัวอย่างการตัดคำภาษาไทย อัลกอริทึม deepcut, newmm, longest, pyicu, attacut – PyThaiNLP ep.2

ใน ep นี้เราจะมาเรียนรู้ หนึ่งในงาน NLP ภาษาไทย ที่เป็นที่ต้องการมากที่สุด เนื่องจากภาษาไทย เป็นภาษาที่เขียนติดกันหมด ไม่มีการเว้นคำด้วย Space เหมือนภาษาอังกฤษ ทำให้การตัดคำภาษาไทย หรือ Tokenization มีความซับซ้อน และ การตัดคำที่ถูกต้องมีความสำคัญ ต่อการนำข้อมูลคำศัพท์ ไปประมวลผลต่อ เช่น Feed เข้าโมเดล Machine Learning, Deep Learning ต่อไป
Recurrent Neural Network (RNN) คืออะไร Gated Recurrent Unit (GRU) คืออะไร สอนสร้าง RNN ถึง GRU ด้วยภาษา Python – NLP ep.9
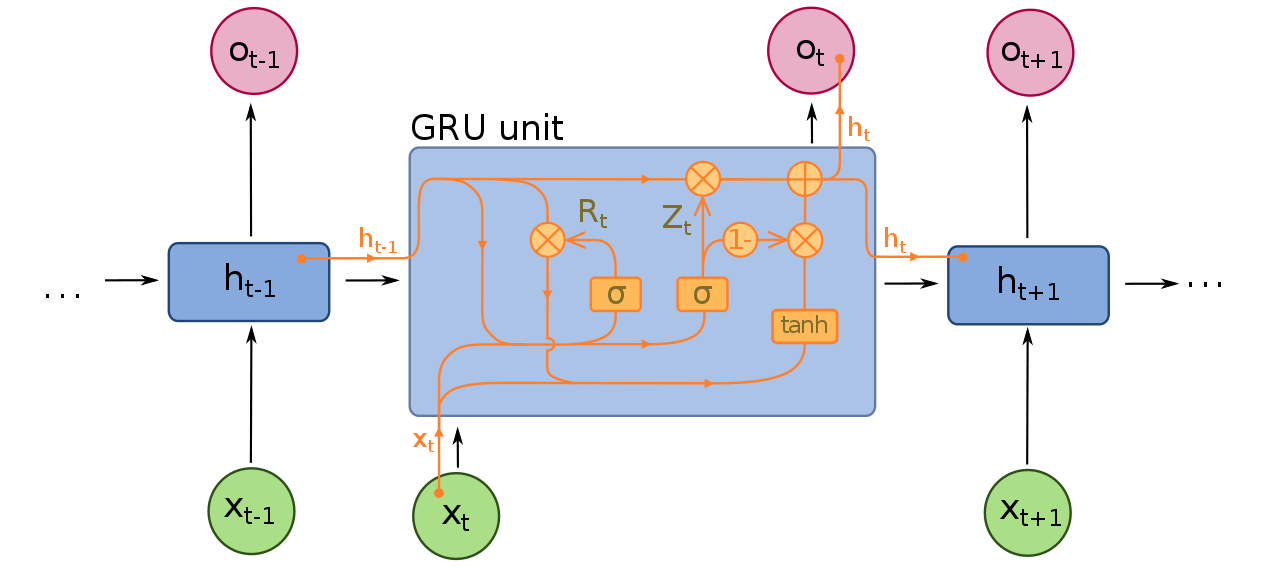
ใน ep นี้เราจะมาสร้าง Artificial Neural Network แบบ Recurrent Neural Network (RNN) กันแต่ต้น ด้วยภาษา Python เริ่มตั้งแต่ ปัญหาว่าทำไมต้องมี RNN พื้นฐานแนวคิด ศึกษาการทำงานของ RNN แบบง่าย ข้อดี ข้อเสีย แล้วพัฒนาโมเดล ปรับปรุง แก้ไขข้อจำกัดของโมเดล RNN แต่ละแบบ ไปจนถึง Gated Recurrent Unit (GRU)
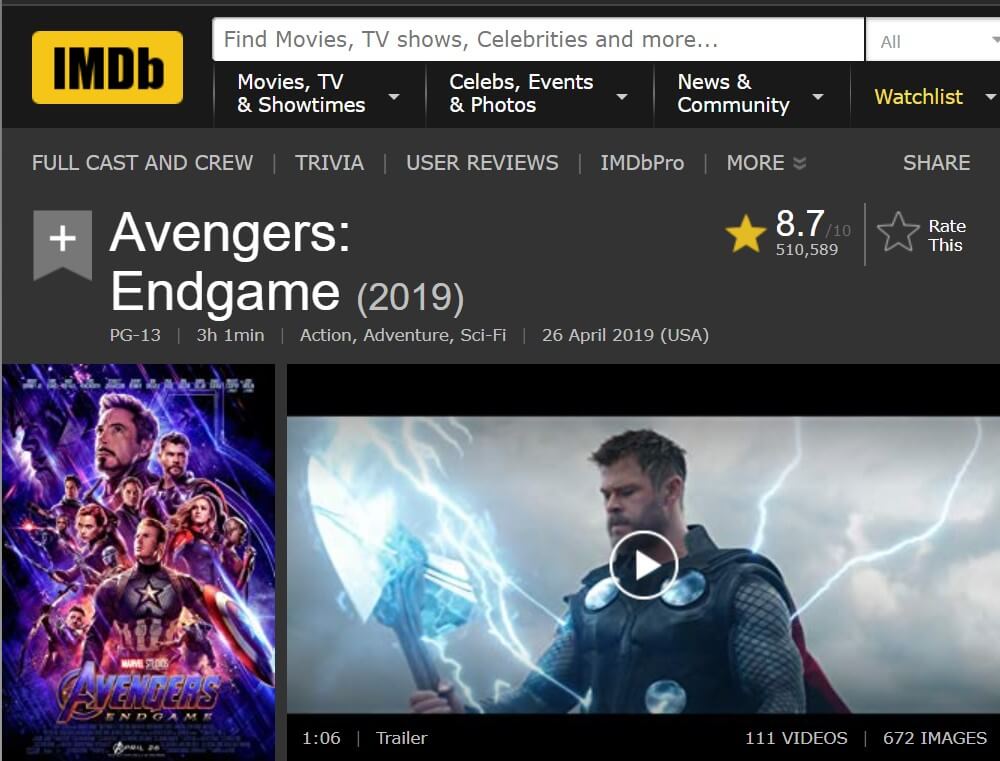
Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย AWD_LSTM Deep Neural Network เทรนแบบ ULMFiT Transfer Learning – NLP ep.8
ใน ep ที่แล้วเราใช้ Naive Bayes และ Logistic Regression ที่เป็นอัลกอริทึมที่เป็นที่นิยมก่อนยุค Deep Learning แต่ใน ep นี้เราจะเปลี่ยนมาใช้ Deep Neural Network แทนว่าจะมีประสิทธิภาพต่างกันอย่างไร
N-Gram คืออะไร Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แบบ N-Gram (Trigram, Bigram, Unigram) ด้วย Naive Bayes, Logistic Regression – NLP ep.6
ใน ep ที่แล้ว Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย Naive Bayes และ Logistic Regression เราใช้ 1 Token ต่อ 1 คำ เรียกว่า Unigram แต่ใน ep นี้ เราจะมาเรียนรู้ N-Gram ในงาน Sentiment Classification ด้วยอัลกอริทึมเดียวกัน ep ที่แล้ว
Sentiment Classification วิเคราะห์รีวิวหนัง IMDB แง่บวก แง่ลบ ด้วย Naive Bayes และ Logistic Regression – NLP ep.5
ใน ep นี้ เราจะใช้ความรู้จาก ep ก่อน ในการสร้าง Term-Document Matrix ด้วย CountVectorizer ด้วยข้อมูลรีวิวหนัง IMDB แล้วนำ Term-Document Matrix ที่ได้ มาวิเคราะห์ Sentiment Classification ว่าเป็นรีวิวแง่บวก หรือแง่ลบ (positive/negative) ด้วยเทคนิค Naive Bayes และ Logistic Regression
Stemming คืออะไร Lemmatization คืออะไร Stemming และ Lemmatization ต่างกันอย่างไร – NLP ep.3

ตามหลักตามไวยากรณ์ภาษาอังกฤษ คำหนึ่งคำจะแปรไปได้หลายรูปแบบ เช่น organize, organizes, organized, organizing นอกจากนั้นคำยังสามารถแปลงเป็นกลุ่มคำ ที่มาจากรากศัพท์เดียวกันได้อีกหลายรูปแบบ เช่น democracy, democratic, democratization ในงาน NLP ถ้าเราต้องการค้นหาคำบางคำในกลุ่ม แล้วอยากให้ได้ผลลัพธ์ครอบคลุมทุกคำทั้งกลุ่ม แล้วเราจะทำอย่างไร
Stop Words คืออะไร ใน Natural Language Processing – NLP ep.2

Natural Language Processing (NLP) ในสมัยก่อนยุค Deep Learning เป็นที่นิยม นักวิจัยมักจะใช้วิธี Hand Engineer กับข้อมูล ในงาน NLP จะมีการเขียนโปรแกรมผูก Logic กฏระเบียบ ไวยากรณ์ ไว้หลายอย่างในโปรแกรม มีการตัดสินใจกำหนด Assumption / Bias หลายอย่าง หนึ่งในนั้นคือ Stop Words ตามรายการที่กำหนด สามารถตัดทิ้งได้ ไม่สำคัญกับความหมายของเนื้อหา ทำให้ลดจำนวนคำศัพท์ ลดความซับซ้อนของโปรแกรมลง
Sentiment Analysis คืออะไร สอน Sentiment Analysis วิเคราะห์ความรู้สึก จากรีวิวหนัง IMDB ด้วย ULMFiT – Sentiment Analysis ep.1
ในยุคอินเตอร์เน็ต ยุคโซเชียลอย่างปัจจุบัน เราสามารถประยุกต์ใช้ Sentiment Analysis ได้อย่างหลากหลาย ไม่ว่าจะเป็นธุรกิจโรงหนัง วิเคราะห์ความรู้สึกลูกค้าหลังจากที่ดูหนัง, ภาคการตลาดวิเคราะห์ฟีดแบ็คของแคมเปญ, ภาคการเมืองใช้ในการวิเคราะห์ ความนิยม คะแนนเสียง, ภาคการเงินวิเคราะห์ข่าวธุรกิจสำหรับวางแผนลงทุน ไปจนถึง การแพทย์ วิเคราะห์ความรู้สึกผู้ป่วย