ใน ep นี้เราจะมาศึกษาอีก Concept นึงที่สำคัญของ NLP คือ Language Model หรือ โมเดลของภาษา ซึ่งถ้าโมเดลของเรามีความสามารถที่จะเข้าใจภาษาโดยภาพรวมได้ดีระดับหนึ่งแล้ว ก็จะส่งผลให้โมเดลนั้นทำงานเฉพาะทาง เช่น Classification, Sentiment Analysis, Machine Translation, Question-Answer ได้ดีขึ้นไปด้วยในตัว
Language Model คืออะไร
Language Model คือ โมเดลว่าภาษานั้นเป็นอย่างไร ในทางสถิติคือ Probability Distribution ของลำดับของคำต่าง ๆ ว่าน่าจะเป็นคำอะไร เช่น ถ้าเราเข้าใจภาษาอังกฤษบ้าง เราก็จะพอเดาได้ว่าคำอะไรน่าจะอยู่ในช่องว่าง Somsak is a tall ______. และคำอะไรไม่น่าจะอยู่
ในทางปฏิบัติ เราสามารถใช้วิธี Bag-of-word ดูทีละคำ (Uni-Gram) ทีละหลาย ๆ คำ N-Gram ดูคำที่มาก่อน ดูคำที่มาทีหลัง หรือทั้งสองทิศทาง Bi-direction และใช้โมเดลคณิตศาสตร์ได้หลากหลาย
แต่ในเคสนี้ เราจะใช้ Neural Network แบบ Recurrent Neural Network – RNN แบบหนึ่ง เรียกว่า AWD_LSTM ที่ถูกเทรนด้วย Corpus ข้อความจาก Dumps Wikipedia ภาษาไทย โดยให้โมเดลเดาคำต่อไปเรื่อย ๆ (เป็น Label แบบ Self-supervised Learning)
เมื่อเราได้ Language Model จาก Wikipedia ภาษาไทย มาแล้ว เราสามารถใส่ข้อความภาษาไทยเริ่มต้นเข้าไปให้ Language Model เดาคำที่น่าจะเป็นคำต่อไป หรือก็คือ Generate Text สร้างข้อความใหม่ต่อ ๆ ไปได้
AWD_LSTM Model Architecture
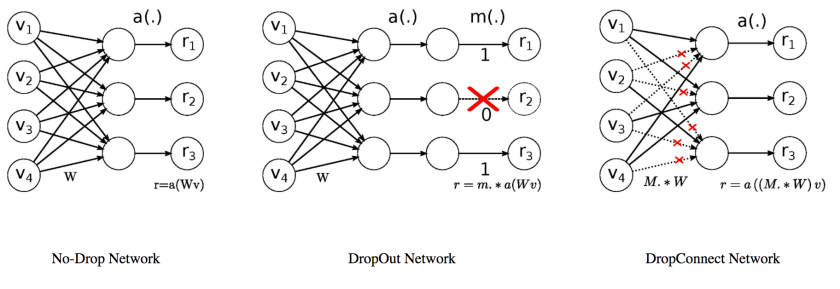
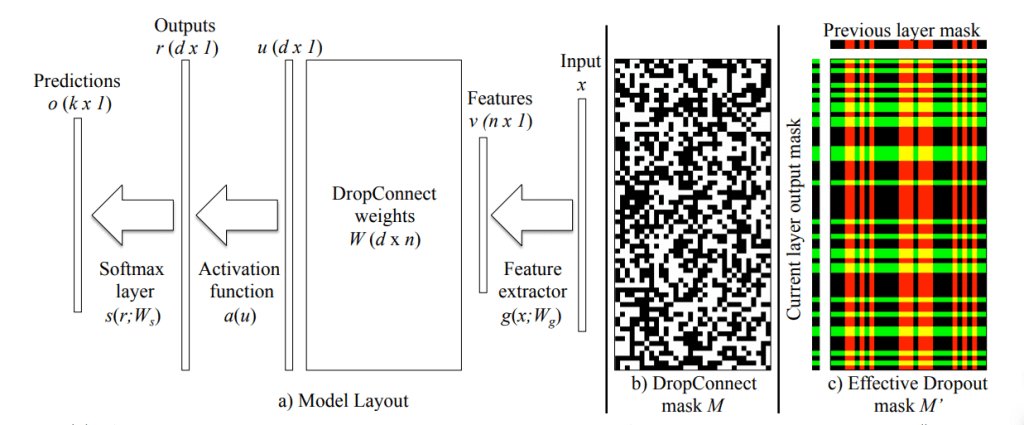
AWD_LSTM เป็น LSTM / Recurrent Neural Network (RNN) แบบหนึ่ง ที่มีการใช้ DropOut / DropConnect หลากหลายแบบภายในส่วนต่าง ๆ ของโมเดล อย่างชาญฉลาด จะอธิบายต่อไป