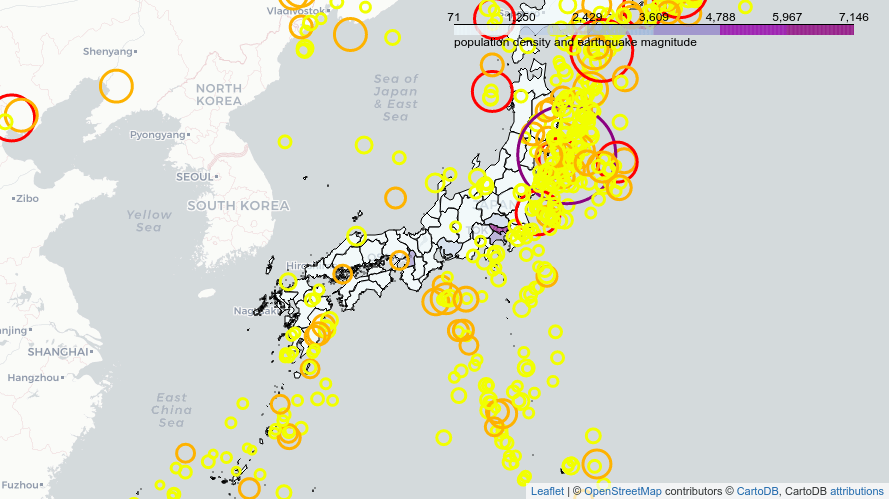
ใน ep นี้ เราจะสมมติตัวเองเป็น นักผังเมืองทางด้านความปลอดภัย ในประเทศญี่ปุ่น เราจะมาวิเคราะห์กันว่าพื้นที่ไหนของญี่ปุ่น ต้องการเสริมกำลังป้องกันสาธาณภัยทางด้านแผ่นดินไหวเป็นพิเศษ เสริมโครงสร้างอาคารป้องกันแผ่นดินไหวเป็นพิเศษ
Category Archives: Data Science
Coordinate Reference System (CRS) คืออะไร Map Projection คืออะไร สอน GeoPandas แปลง CRS ข้อมูลภูมิศาสตร์ GeoData – GeoSpatial ep.2
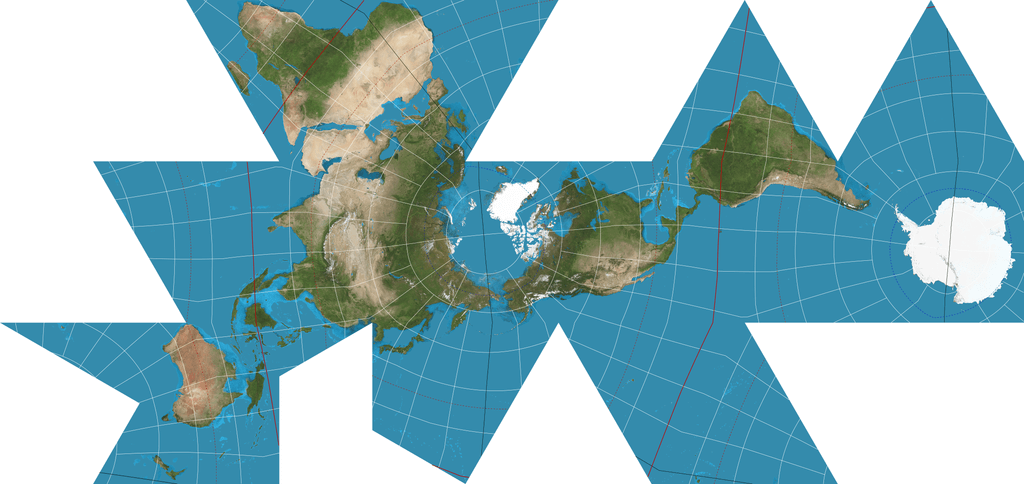
แผนที่ที่เราใช้กันอยู่ทุกวันนี้ คือการฉายภาพของพื้นผิวโลกลงบนพื้นที่ 2 มิติ เหมือนแผ่นกระดาษ แต่โลกของเราจริง ๆ แล้วเป็นทรงกลม 3 มิติ เหมือนผลส้ม ดังนั้นเราจึงต้องมีวิธีการเรียกว่า Map Projection เพื่อ Render พื้นผิวโค้ง 3 มิติ แปลงให้เป็นพื้นผิวเรียบ 2 มิติ เนื่องจากเป็นการแปลง 3 มิติเป็น 2 มิติ จะต้องมีข้อมูลสูญหายไป แล้ว Projection แบบไหนที่ดีที่สุด เราจะเลือก Projection อย่างไร
Geospatial Data คืออะไร สอน GeoPandas วาดแผนที่ข้อมูลภูมิศาสตร์ ใน Google Colab ดึง Geographic Dataset จาก Kaggle – GeoSpatial ep.1
ใน ep นี้ เราจะมาเรียนรู้เกี่ยวกับ Geospatial Data ข้อมูลภูมิศาสตร์ หรือ ข้อมูลที่มีพิกัดตำแหน่งบนแผนที่บนโลกใบนี้ติดมาด้วย รวมถึงวิธีการ Wrangle ข้อมูล และการทำ Visualize ข้อมูล ออกมาเป็นภาพให้คนทั่วไปเข้าใจได้ง่าย ข้อมูลทางภูมิศาสตร์ช่วยให้เราตัดสินใจ ตอบคำถาม แก้ปัญหาต่าง ๆ ที่เกิดขึ้นบนโลกแห่งความเป็นจริงได้ดีมากขึ้น
จัดการหมวดหมู่เล็ก ๆ ยิบย่อย รวมข้อมูลหมวดหมู่ Category เล็ก ๆ เป็นหมวดหมู่ Other ก่อนป้อนเทรน Machine Learning – Preprocessing ep.4
ในหลาย ๆ Dataset เราจะพบว่าข้อมูลแบบ Category มีการแตกยิบย่อยมากเกินไป เช่น บาง Category มีแค่ 1 หรือ 2 Record เท่านั้น หรือ Category เล็ก จำนวน Record แตกต่างกับ Category ใหญ่ ๆ หลายร้อย หลายพันเท่า ข้อมูล Category เล็ก ๆ ยิบย่อยเหล่านี้ อาจจะไม่ได้ช่วยโมเดล Machine Learning ในการเรียนรู้ก็ได้ ทางแก้คือ เราจะ Group รวม Category เล็ก ๆ เหล่านั้นรวมออกมาเป็น Category ใหม่ ตั้งชื่อว่า Other
สำรวจข้อมูล Exploratory Data Analysis (EDA) ด้วย Pandas Profiling วิเคราะห์ Pandas DataFrame – Pandas ep.6
เมื่อเราได้ Dataset ใหม่มา สิ่งแรกที่เราควรทำ คือ Exploratory Data Analysis (EDA) ทำความเข้าใจข้อมูล ในแต่ละ Feaure เช่น ข้อมูลเป็นชนิดอะไร, ข้อมูลเป็นแบบต่อเนื่องหรือไม่ต่อเนื่อง, ช่วงของข้อมูลกว้างแค่ไหน, การกระจายของข้อมูลเป็นอย่างไร, มีข้อมูลขาดหายไปเยอะแค่ไหน, แต่ละ Feature เชื่อมโยงกันอย่างไร การวิเคราะห์ทั้งหมดนี้ค่อนข้างซับซ้อน และซ้ำซ้อนเหมือนกันในทุก ๆ Dataset จะมีวิธีไหนที่จะทำให้งานซ้ำ ๆ เหล่านี้ง่ายขึ้น
MNIST คืออะไร
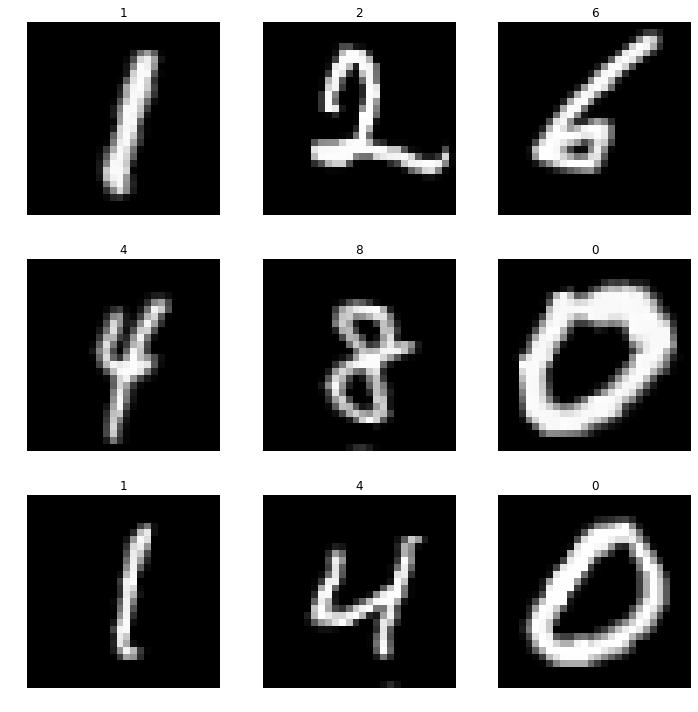
MNIST Database คือ ชุดข้อมูลรูปภาพของตัวเลขอารบิก 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ที่เขียนด้วยลายมือ 70,000 รูป MNIST คือ ชุดข้อมูลสำหรับไว้เทรน Artificial Intelligence (AI) เกี่ยวกับ Computer Vision / Image Processing
Categorize การเตรียมข้อมูลหมวดหมู่ Categorical Data ด้วย One-Hot Encoding, Map ก่อนเทรน Machine Learning – Preprocessing ep.3
นอกเหนือจากข้อมูลตัวเลข Cardinal ค่าต่อเนื่อง (Continuous) เราจะพบ Feature ที่เป็นข้อมูลค่าไม่ต่อเนื่อง (Discrete) ในรูปแบบตัวเลขแบบ Ordinal, Nominal หรือข้อความ คือ มีค่าที่เป็นไปได้จำกัด ระบุว่าอยู่หมวดหมู่ไหน เช่น วันในสัปดาห์ 1 จันทร์, 2 อังคาร, 3 พุธ, … คือ 1 ใน 7 ค่าเท่านั้น เราจะไม่สามารถทำ Rescale, Normalize แบบใน ep 2 ได้ แล้วเราจะเตรียมข้อมูลชนิดนี้อย่างไรดี ถึงจะป้อนให้ Machine Learning ใช้เทรนได้
Normalization คืออะไร ปรับช่วงข้อมูล Feature Scaling ด้วยวิธี Normalization, Standardization ก่อนเทรน Machine Learning – Preprocessing ep.2
การทำ Feature Scaling คือ วิธีการปรับช่วงขอบเขตของข้อมูลชนิดตัวเลข Cardinal แต่ละ Feature (Field) ให้อยู่ในช่วงเดียวกัน ที่เหมาะกับการนำไปประมวลผลต่อ เข้าสูตรคำนวณได้ง่าย เช่น ช่วง [0, 1] หรือ [-1, 1] ได้ผลลัพธ์อยู่ในช่วงที่กำหนด เรียกว่า Data Normalization นิยมทำในขั้นตอน Preprocessing จัดเตรียมข้อมูล ก่อนป้อนให้โมเดลใช้เทรน
Preprocessing คืออะไร สอนจัดการข้อมูลขาดหาย Missing Value วิธีเติมข้อมูลแทนค่า Null, NA, NaN ก่อนป้อนโมเดล เทรน Machine Learning – Preprocessing ep.1

จาก ep ก่อน ที่เราสอนเรื่อง ใช้ Deep Neural Network วิเคราะห์ข้อมูลแบบ Structure หรือข้อมูลแบบตาราง Tabular Data จะมีงานสำคัญที่ต้องทำก่อนเทรน คือการ Preprocessing จัดเตรียมข้อมูล ซึ่งมีหลายอย่าง เช่น Fillna, Normalize, Categorize, Clipping, Binning, Feature Engineering ต่าง ๆ , etc. ใน ep นี้เราจะมาเรียนรู้กันเรื่อง การจัดการกับข้อมูลไม่ครบ วิธีเติมค่าที่ขาดหายไป หรือ Null
ทดสอบ Metrics ของ Neural Network ด้วยข้อมูลจาก Validation Set ระหว่างการเทรน Machine Learning – Neural Network ep.8
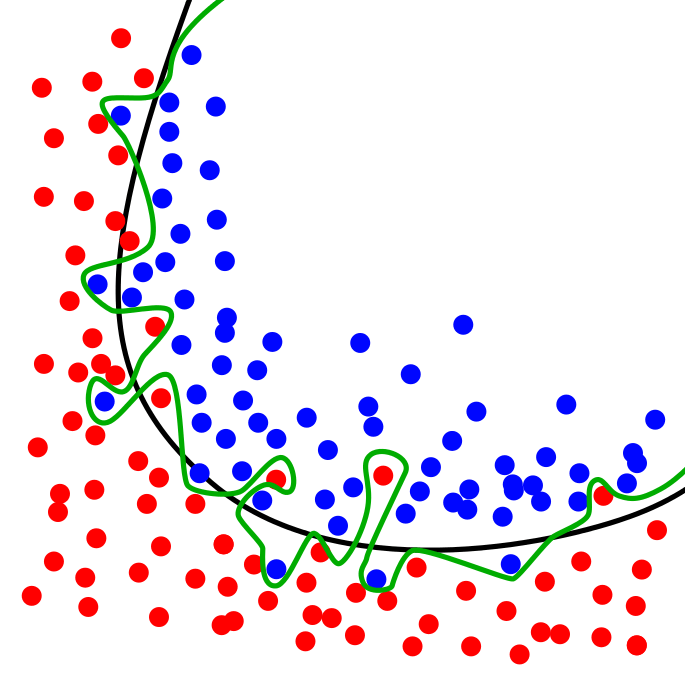
ในการเทรน Machine Learning การทดสอบว่าโมเดล Neural Network ทำงานเป็นอย่างไร ที่ถูกต้องเราไม่ควรเทสกับข้อมูล ใน Training Set ที่เราป้อนให้โมเดลในขณะเทรน เพราะจะทำให้ไม่ได้ค่าที่แท้จริง ถ้าโมเดลใช้วิธีจำข้อสอบ เรียกว่า Overfit เมื่อเทสแล้วจะได้คะแนนสูงผิดปกติ ที่ถูกคือ เราควรเทสกับข้อมูลที่โมเดลไม่เคยเห็นมาก่อน ใน Validation Set ที่เรากันเอาไว้ก่อนหน้าที่จะเริ่มต้นเทรน