
TensorFlow Lite Converter เป็นตัวแปลงโมเดล TensorFlow ตัวเต็ม ให้ย่อลงมาเป็นโมเดลขนาดเล็ก ที่ทำงานได้รวดเร็ว สำหรับรันกับ Interpreter บนอุปกรณ์ Edge Device ที่มี Resource จำกัด ด้วยเทคนิค Quantization โดยพิจารณาจาก Hardware ปลายทาง ที่จะนำโมเดลไป Deploy เช่น อุปกรณ์ IoT Device, มือถือ Mobile, Microcontroller ต่าง ๆ
Tag Archives: signal processing
Quantization คืออะไร Post-Training Quantization มีประโยชน์อย่างไร กับ Deep Neural Network บนอุปกรณ์ Embedded Device, IoT, Edge, มือถือ Mobile – tflite ep.2
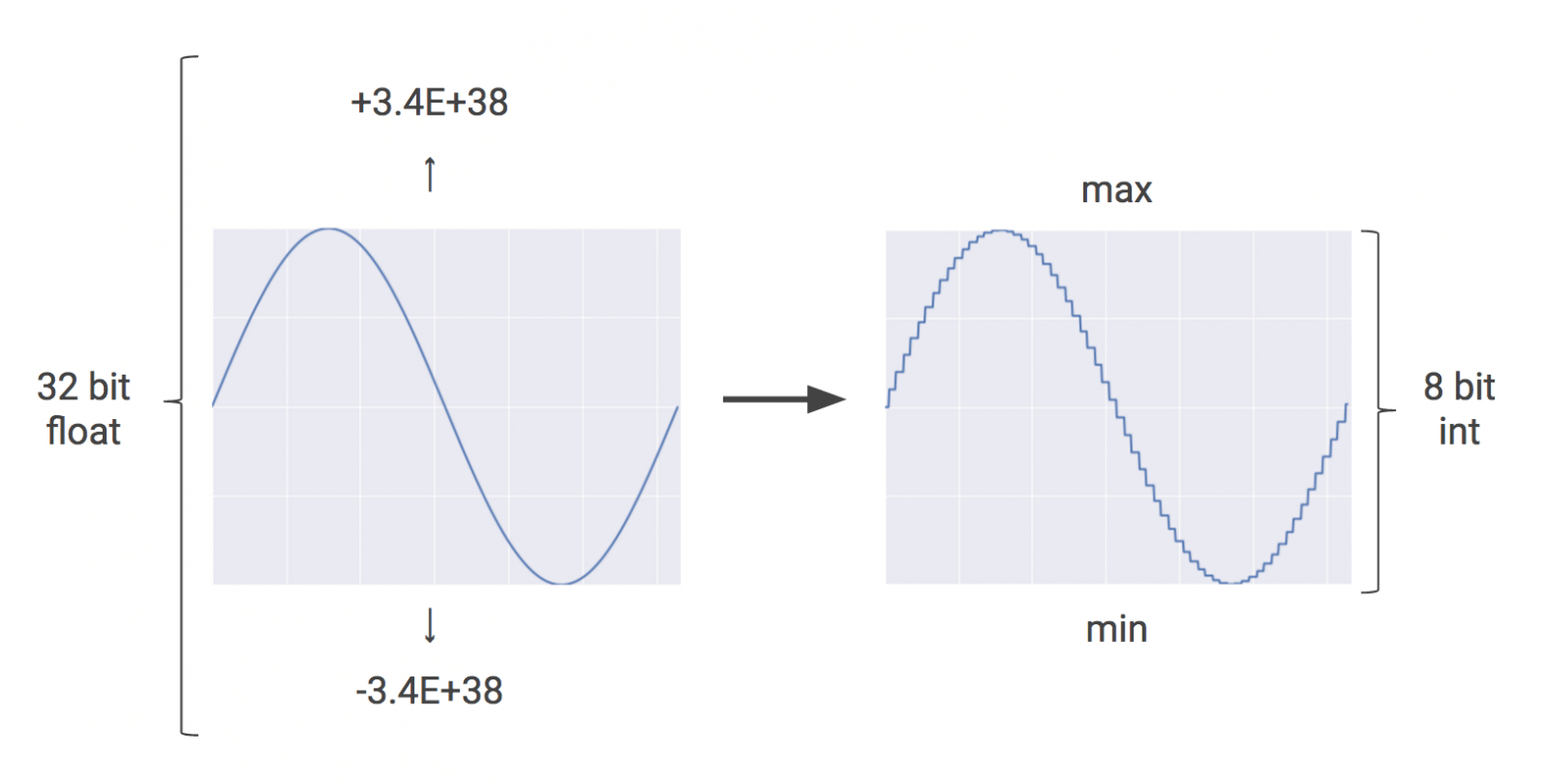
ถ้าข้างนอกมีฝนตกอยู่ เราอาจจะไม่ได้ต้องการทราบว่าฝนกำลังตกกี่เม็ดต่อวินาที เราต้องการทราบแค่เพียงว่า ฝนตกหนัก ฝนตกปานกลาง หรือฝนตกเล็กน้อย เช่นเดียวกับการพยากรณ์ของ Neural Network บ่อยครั้งที่เราไม่ได้ต้องการความแม่นยำขนาด ตัวเลยทศนิยม Floating Point 32 Bit หรือแม้กระทั่ง 16 Bit และในหลาย ๆ งานใช้แค่จำนวนเต็ม Integer 8 Bit ก็เพียงพอแล้ว