ถ้าข้างนอกมีฝนตกอยู่ เราอาจจะไม่ได้ต้องการทราบว่าฝนกำลังตกกี่เม็ดต่อวินาที เราต้องการทราบแค่เพียงว่า ฝนตกหนัก ฝนตกปานกลาง หรือฝนตกเล็กน้อย
เช่นเดียวกับการพยากรณ์ของ Neural Network บ่อยครั้งที่เราไม่ได้ต้องการความแม่นยำขนาด ตัวเลยทศนิยม Floating Point 32 Bit หรือแม้กระทั่ง 16 Bit และในหลาย ๆ งานใช้แค่จำนวนเต็ม Integer 8 Bit ก็เพียงพอแล้ว
Quantization คืออะไร
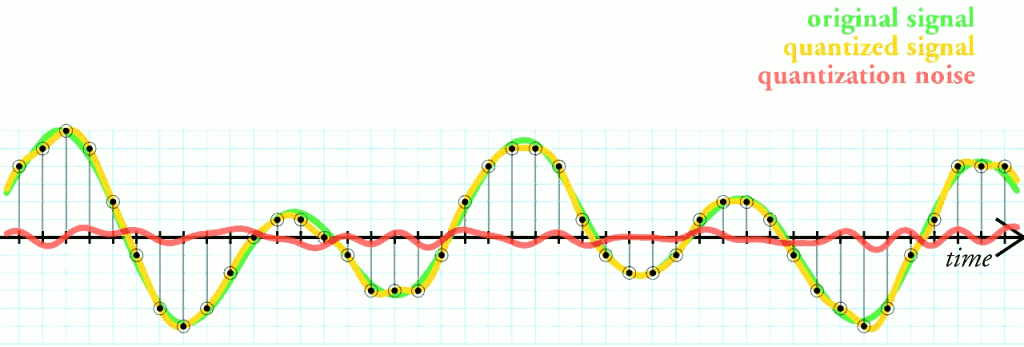
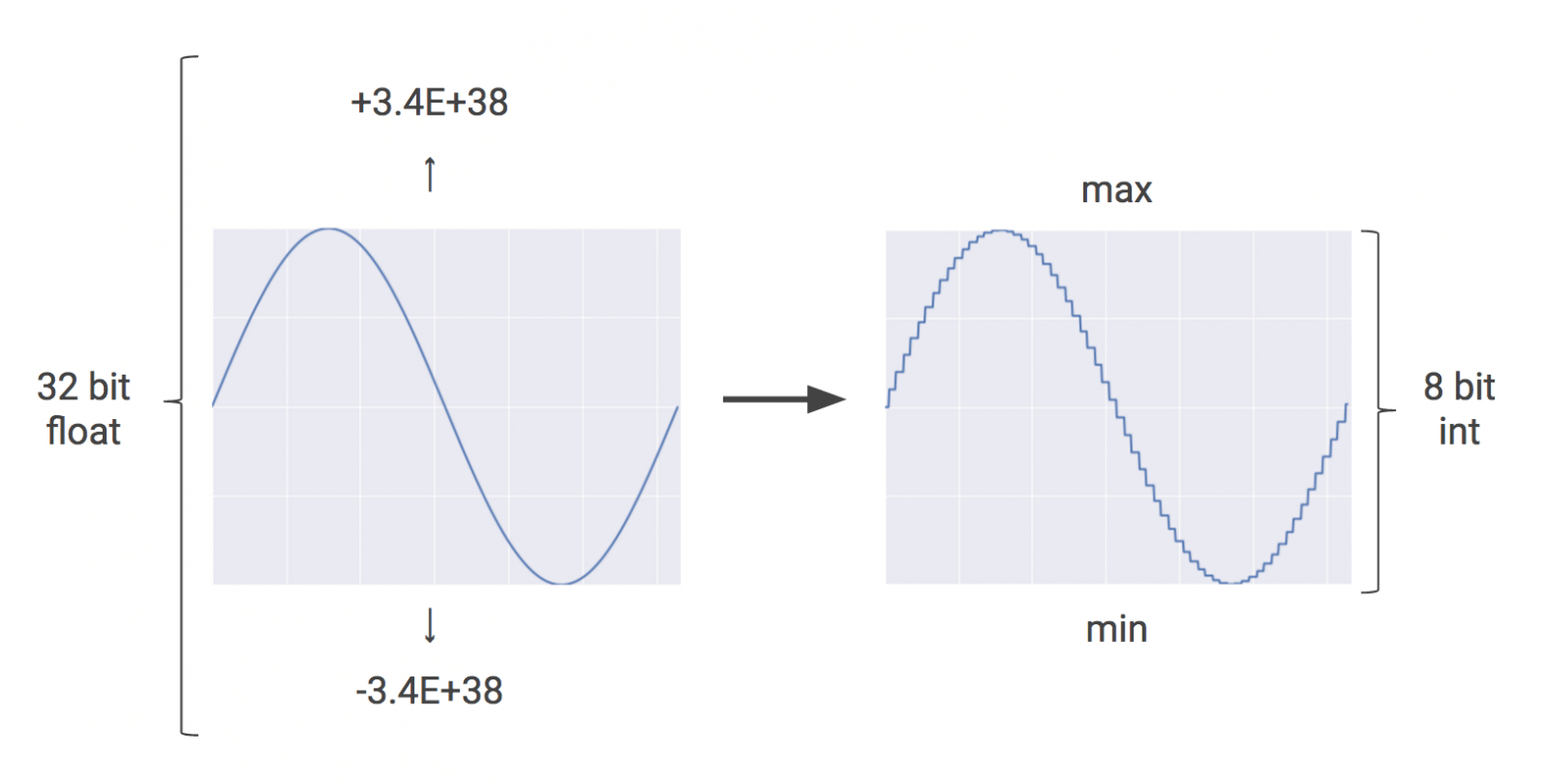
Quantization คือ เทคนิคที่ใช้จำนวนเต็ม Integer 8 Bit ให้การประมาณค่าของจำนวนตัวเลขทศนิยม Floating Point ระหว่างค่าสูงสุด และต่ำสุดในช่วงที่กำหนด เทคนิคนี้เป็นที่นิยมในงาน Signal Processing ใช้ในการแปลง สัญญาณ Analog เป็น Digital
ประโยชน์ของ Post-Training Quantization
Quantization เป็นเครื่องมือสำคัญ ที่จะลดต้นทุนในการทำงานของ Neural Network ลดขนาดโมเดล ลด Memory ที่ใช้ ลดพลังงานที่ใช้ ลดเวลาในการตอบสนอง (Latency) โดยเฉพาะอย่างยิ่งสำหรับงานบนมือถือ และ Embedded ตัวอย่างเช่น เราสามารถทำ Quantization ให้โมเดล Inception ย่อขนาดโมเดลจาก 91 MB เหลือเพียง 23MB หรือ 25% จากต้นฉบับเท่านั้น

การใช้ตัวเลขจำนวนเต็ม Integer แทนตัวเลขทศนิยม Floating Point เป็นการประหยัด Hardware ประมวลผลที่จำเป็นต้องใช้เป็นอย่างมาก และในกรณีที่ GPU รองรับ Int8 สามารถเพิ่มความเร็วได้มากสุดถึง 25 เท่าเลยทีเดียว ถ้ารับความแม่นยำที่ลดลงได้
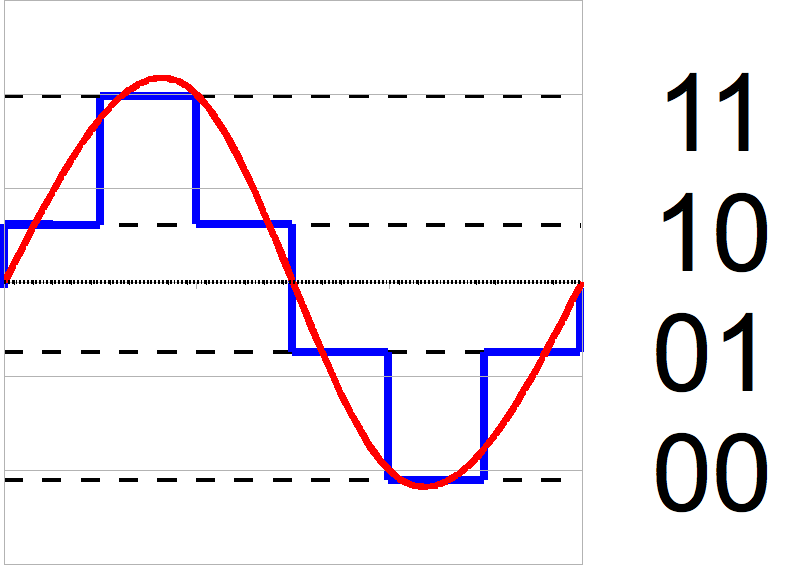
ตัวอย่าง Quantization 2 Bit
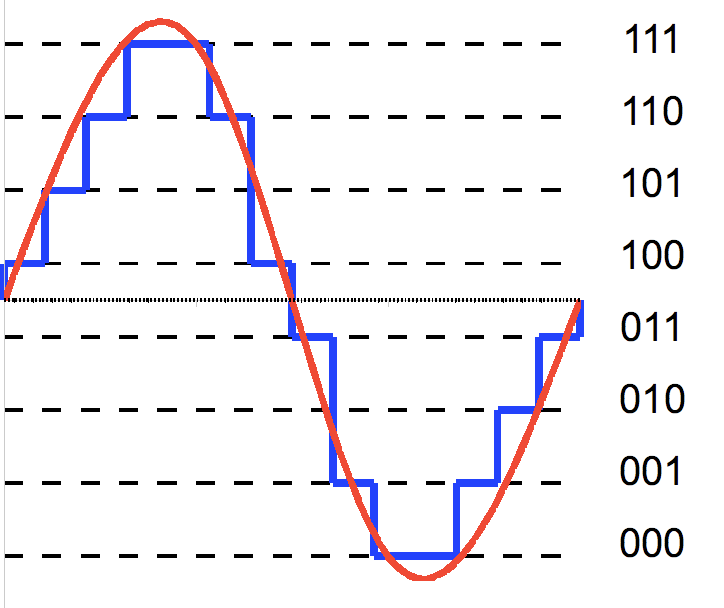
ตัวอย่าง Quantization 3 Bit
Optimization options
มีตัวเลือกในการทำ Post-Training Quantization หลายแบบ มีประโยชน์ และข้อจำกัดที่แตกต่างกัน ดังตารางด้านล่าง
| Technique | Benefits | Hardware |
|---|---|---|
| Weight quantization | 4x smaller, 2-3x speedup, accuracy | CPU |
| Full integer quantization | 4x smaller, 3x+ speedup | CPU, Edge TPU, etc. |
| Float16 quantization | 2x smaller, potential GPU acceleration | CPU/GPU |
ขั้นแรก เราจะ Optimize โมเดล ด้วยการทำ Quantize ลดจำนวน Bit ของ Parameter (Weight quantization) ในโมเดลลง
และถ้าเรามีข้อมูลตัวอย่างเพียงพอ นอกเหนือจาก Parameter เราสามารถ Quantize ข้อมูล และ Activation ได้อีก โดยการให้ชุดข้อมูลตัวอย่าง รันผ่านโมเดล เพื่อเก็บสถิติ Representative Dataset วัด Dynamic Range ของข้อมูล และ Activation สร้าง Input Data Generator เพื่อส่งให้กับ Converter ใช้ในการทำ Integer Quantization ต่อไป
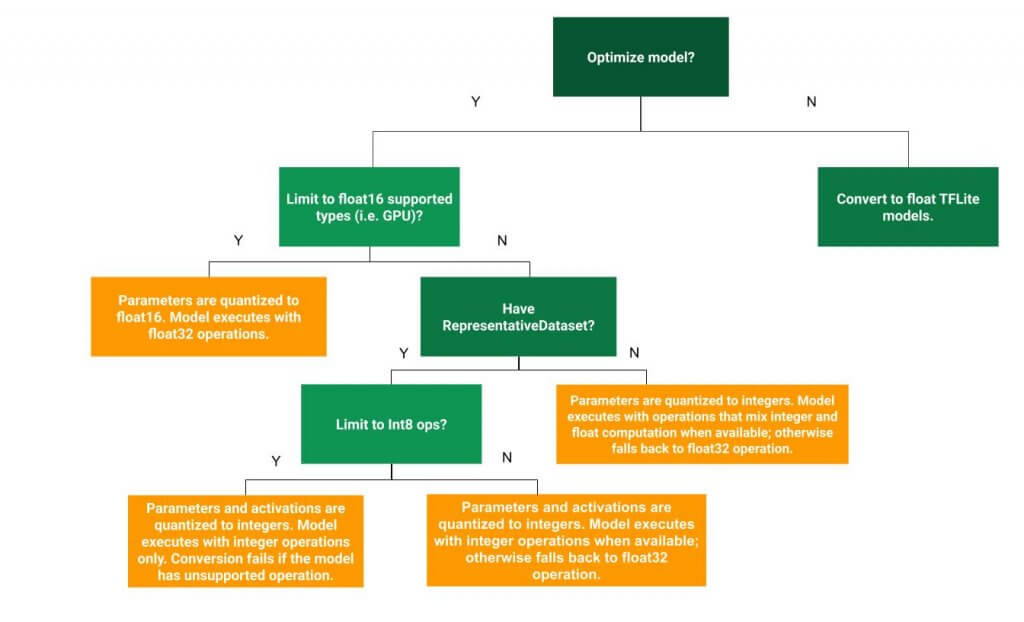
โมเดลที่แปลงแล้ว จะยังรับ Input / Output เป็น Float เหมือนเดิมเพื่อความสะดวก จะได้ไม่ต้องแก้โปรแกรม
และ ในโมเดล ถ้า Ops ไหน ที่ไม่มี Quantized Implementation ก็จะใช้เป็น Floating Point Implementation เหมือนเดิม แต่ Float16 quantization ลดขนาดจาก Float32 เป็น Float16 แบบนี้จะทำให้การ Convert โมเดลทำได้อย่างราบรื่น แต่ก็จะจำกัดให้รันได้เฉพาะ Hardware ที่รองรับ Floating Point

ในการเลือกเทคนิค Quantization ควรพิจารณาจาก Hardware ที่จะนำโมเดลไป Deploy และ Ops ที่ใช้ในโมเดล ว่ามี Quantized Implementation ครบทุก Ops หรือไม่
Credit
- https://www.tensorflow.org/lite/performance/post_training_quantization
- https://cloud.google.com/blog/products/gcp/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
- https://pytorch.org/docs/stable/quantization.html
- https://pytorch.org/tutorials/advanced/static_quantization_tutorial.html

